Primero un poco de contexto. El cubo de Rubik es un rompecabezas tridimensional, creado en 1974 por el inventor húngaro E o Rubik. Su objetivo consiste en que todos los cuadrados de cada cara del cubo sean del mismo color. El juguete es famoso a nivel mundial con más de 350 millones de unidades vendidas en todo el planeta.
n
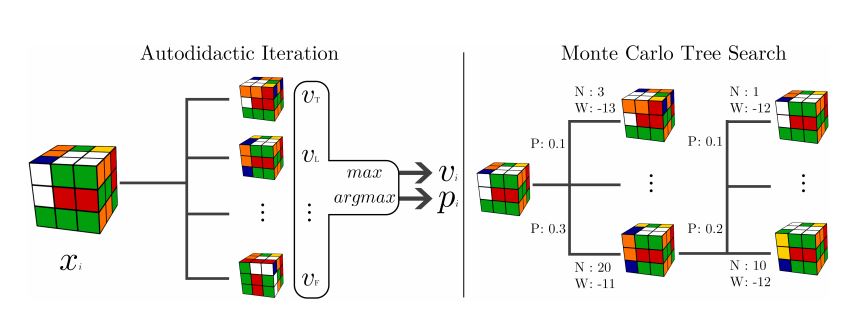
Gráfico: Iteración autodidacta frente al árbol de búsqueda Monte Carlo.
nPero además de su función como pasatiempo, el cubo de Rubik también generó mucho interés entre informáticos y matemáticos. Los científicos querían saber cuál es el menor número de movimientos necesarios para resolverlo desde cualquier posición. La respuesta, demostrada en 2014, resultó ser 26.
nOtro desafío común consiste en diseñar algoritmos que puedan resolverlo desde cualquier posición. Después de inventar el juguete, el propio Rubik solo tardó un mes en diseñar uno capaz de hacerlo. Pero para lograrlo, su algoritmo debía ser construido a mano por un humano.
nHace poco, los informáticos intentaron encontrar una estrategia para que las máquinas fueran capaces de aprender a resolver el puzle por sí solas. Para ello, podría emplearse el mismo enfoque que ya ha sorprendido al mundo con máquinas derrotando a los campeones mundiales de juegos como el ajedrez y Go (ver El día que la humanidad fue derrotada por una inteligencia artificial).
nEn estos escenarios, una máquina de aprendizaje profundo recibe las reglas del juego y luego juega contra sí misma. Un punto clave en su aprendizaje se basa en que la máquina recibe una recompensa cada vez que avanza en la dirección correcta. El enfoque, conocido como aprendizaje reforzado, es muy importante porque ayuda a la máquina a distinguir cuándo está jugando bien y cuándo lo está haciendo mal. En otras palabras, ayuda a la máquina a aprender.
nPero en muchas situaciones del mundo real el aprendizaje reforzado no funciona. Las recompensas a menudo son complicadas o difíciles de determinar. Por ejemplo, los giros aleatorios de un cubo de Rubik no se pueden recompensar fácilmente, ya que es difícil juzgar si la nueva configuración se acerca más a una solución. Y una secuencia de giros aleatorios puede continuar durante mucho tiempo sin llegar a una solución, por lo que la recompensa por cumplir el objetivo final solo puede ofrecerse en raras ocasiones. Por el contrario, aunque en el ajedrez hay múltiples opciones, cada movimiento puede ser evaluado y recompensado en consecuencia. Pero ese no es el caso del cubo de Rubik.
nPara resolver este problema, el equipo del investigador de la Universidad de Califo ia en Irvine (EE. UU.) Stephen McAleer ha creado un nuevo tipo de técnica de aprendizaje profundo, la "iteración autodidacta", que logra enseñar a una máquina a resolver un cubo de Rubik sin ayuda humana. El truco consiste en encontrar la forma de que la máquina diseñe su propio sistema de recompensas.
nAsí es como funciona. En un cubo no resuelto, la máquina debe decidir si un movimiento específico mejora la configuración existente. Pero para tomar esa decisión, debe ser capaz de evaluar el movimiento.
nPara lograrlo, la iteración autodidacta empieza con un cubo resuelto y trabaja hacia atrás para encontrar una configuración que sea similar al movimiento propuesto. Aunque el enfoque no es perfecto, permite que el sistema descubra qué movimientos son generalmente mejores que otros. Cuando el sistema ya está entrenado, la red utiliza un árbol de búsqueda estándar para identificar los mejores movimientos para cada configuración.
nEl resultado es un algoritmo que funciona bastante bien. McAleer y su equipo explican: "Nuestro algoritmo es capaz de resolver el 100 % de los cubos aleatoriamente codificados en una media de unos 30 movimientos, siempre menos o como mucho los mismos movimientos que necesita una máquina menores o iguales a los sistemas basados en el conocimiento humano".
nEs un trabajo interesante porque podría aplicarse en una variedad de tareas con las que el aprendizaje profundo ha tenido problemas, incluidos otros rompecabezas como Sokoban, juegos como La Venganza de Montezuma y problemas como la factorización de números primos.
nDe hecho, McAleer y su equipo ya tienen otros objetivos en mente: "Estamos trabajando para ampliar este método para encontrar soluciones aproximadas a otros problemas de optimización combinatoria, como la predicción de la estructura terciaria de una proteína". Pero no está claro si estos problemas podrán ser abordados por este enfoque, ya que, por lo general, no se benefician de una prueba de que se puedan resolver en un pequeño número de movimientos, como lo hace el problema del cubo de Rubik. Eso, sin duda, funcionó a favor del equipo.
nMcAleer y su equipo argumentan que su enfoque es una forma de razonar sobre los problemas. Señalan que una definición de razonamiento es: "manipular algebraicamente el conocimiento previamente adquirido para responder una nueva pregunta". Y afirman que eso es justo lo que hace su algoritmo, al que han bautizado como DeepCube. Por el contrario, las máquinas convencionales de aprendizaje profundo simplemente reconocen ciertos patrones. El equipo señala: "DeepCube es capaz de aprender a razonar para resolver un ento o complejo con solo un estado de recompensa utilizando el aprendizaje reforzado".
nPuede que sea así. Pero para demostrarlo, habrá que ver cómo rinde su enfoque cuando se enfrente a problemas más complejos como el plegamiento de proteínas. Estaremos atentos para ver cómo funciona.
nRef: arxiv.org/abs/1805.07470: Solving the Rubik's Cube Without Human Knowledge
n