UU.) Dawn Song en la que contó cómo había usado unas simples pegatinas para engañar a un coche autónomo para que creyera que una señal de alto en realidad era un límite de velocidad de 50 kilómetros por hora. También explicó que logró usar mensajes específicos para que un modelo basado en texto revelara datos confidenciales, como los números de las tarjetas de crédito.
nA medida que los sistemas de aprendizaje profundo han ido penetrando en nuestras vidas, los investigadores han empezado a alertar de que los ejemplos antagónicos pueden afectar a desde simples clasificadores de imágenes hasta a los sistemas de diagnóstico de cáncer, con consecuencias desde benignas hasta mortales. Pero a pesar del peligro, los ejemplos antagónicos no se han estudiado demasiado. Así que algunos investigadores han empezado a pensar en cómo resolver el problema, si es que se puede.
nUn nuevo estudio del MIT (EE. UU.) apunta un posible camino que podría superar este desafío. Nos permitiría crear modelos de aprendizaje profundo bastante más resistentes y mucho más difíciles de manipular. Pero para entender cómo funciona, primero repasaremos los conceptos básicos de los ejemplos antagónicos.
nComo ya hemos señalado muchas veces, el poder del aprendizaje profundo proviene de su excelente capacidad de reconocer patrones en los datos. Si en una red neuronal se introducen decenas de miles de fotos de animales etiquetados, aprenderá qué patrones se asocian a un panda y cuáles a un mono. Luego podrá usar esos patrones para identificar nuevas imágenes de animales que nunca antes había visto.
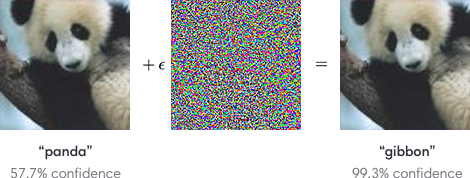
nPero los modelos de aprendizaje profundo también resultan muy sensibles. Dado que un sistema de reconocimiento de imágenes se basa únicamente en los patrones de los píxeles en lugar de en una comprensión conceptual más profunda de lo que ve, es fácil engañar al sistema para que vea algo completamente diferente. Basta con alterar los patrones de forma correcta. Un ejemplo clásico sería añadir un poco de ruido a la imagen de un panda, lo que provocará que un sistema lo confunda con un gibón con casi un 100 % de confianza. El ruido, en este caso, representa un ataque antagónico.
n
Aunque hace algunos años desde que los investigadores son conscientes del problema, especialmente en los sistemas de visión artificial, hasta ahora no han sido capaces de eliminar esas vulnerabilidades. De hecho, un trabajo presentado la semana pasada en una de las principales conferencias de investigación de inteligencia artificial (IA), la ICLR, planteó la cuestión de si los ataques antagónicos eran inevitables. Parece que no importa cuántas imágenes de pandas se introduzcan a un clasificador de imágenes, siempre habrá algún tipo de interferencia diseñada para atacar al sistema.
nPero el nuevo estudio del MIT demuestra que este punto de vista era erróneo. En lugar de pensar en maneras de acumular más y mejores datos de entrenamiento para alimentar nuestro sistema, deberíamos replantea os la forma en la que los entrenamos.
nPara demostrarlo, el equipo identificó una característica bastante interesante de los ejemplos antagónicos que ayuda a comprender por qué son tan efectivos. El ruido aparentemente aleatorio o las pegatinas que provocan errores de clasificación, en realidad, explotan patrones minúsculos muy precisos que el sistema de imágenes ha aprendido a asociar directamente con algunos objetos específicos. En otras palabras, si la máquina ve un gibón donde nosotros vemos un panda, en realidad no está funcionando de forma incorrecta. Lo que ella ve es un patrón de píxeles, imperceptible para los humanos, que se produjo durante el entrenamiento con mucha más frecuencia en las fotos de gibón que en las fotos de panda.
nPara explicarlo mejor, los investigadores crearon un conjunto de datos con imágenes de perros a los que cambiaron pequeños detalles para que un clasificador de imágenes estándar los confundiera con gatos. Luego etiquetaron erróneamente las imágenes como gatos y las usaron para entrenar a otra red neuronal desde cero. Después del entrenamiento, mostraron las imágenes reales de los gatos a la red neuronal que las identificó correctamente como gatos.
nEste resultado revela que en cada conjunto de datos, existían dos tipos de correlaciones: los patrones que realmente se correlacionan con el significado de los datos, como los bigotes de un gato o las manchas en el pelo de un panda; y por otro lado, los patrones que aparecen dentro de los datos de entrenamiento que no se replican en otros contextos. Estas últimas correlaciones "engañosas" son las que se usan en los ataques antagónicos. En la imagen anterior, por ejemplo, el ataque aprovecha un patrón de píxeles correlacionado falsamente con gibones al esconder esos píxeles imperceptibles dentro de la imagen del panda. El sistema de reconocimiento, entrenado para reconocer el patrón engañoso, lo retoma y asume que está viendo a un gibón.
nEsto indica que, si queremos eliminar el riesgo de ataques antagónicos, debemos cambiar la forma en la que entrenamos a nuestros modelos. Actualmente, dejamos que la red neuronal elija las correlaciones que quiera para identificar objetos en una imagen. El resultado es que no tenemos control sobre las correlaciones que encuentra ni sobre si son reales o engañosas. Pero si entrenamos a nuestros modelos para recordar solo los patrones reales, aquellos verdaderamente vinculados con el significado de los píxeles, teóricamente sería posible crear sistemas de aprendizaje profundo que no se pudieran manipular de esta manera con fines perjudiciales.
nDe hecho, cuando los investigadores probaron esta idea utilizando solo correlaciones reales para entrenar a su modelo, mitigaron su vulnerabilidad, pues sólo lograron manipularlo la mitad de las veces. Por el contrario, un modelo entrenado en ambas correlaciones, la real y la falsa, podría manipularse el 95 % del tiempo. Dicho de otra manera, parece que los ejemplos antagónicos no son inevitables. Pero hace falta más trabajo para eliminarlos por completo.
n