
COMPAS reveló tener sesgos hacia los acusados negros, así que hemos intentado rediseñarlo para que sus resultados sean más justos. Pero, al estar entrenado con datos históricos injustos resulta imposible que ofrezca las mismas tasas de acierto y error mientras trata a todos los colectivos de la misma manera
Cuando somos niños, desarrollamos un sentido de lo que significa "justicia". Es un concepto que aprendemos muy pronto, a medida que nos adaptamos al mundo que nos rodea. Algo nos parece justo o no.
Pero cada vez más, los algoritmos han empezado a arbitrar la justicia para nosotros; deciden quién va a ver un anuncio de viviendas, quién es contratado o despedido e incluso quién debe ir a la cárcel. En consecuencia, a las personas que crean esos algoritmos (ingenieros de software) se les pide que expresen en su código lo que significa ser justo. Así que los reguladores del mundo están empezando a tener que lidiar con la siguiente pregunta: ¿Cómo se puede cuantificar matemáticamente la justicia?
Queremos ofrecer una respuesta, y para eso vamos a analizar un algoritmo real, el que se utiliza para decidir quién debe ir a la cárcel. Se conoce como COMPAS, y es una de las varias herramientas de "evaluación de riesgo" que se usan en el sistema de justicia penal de EE. UU.
En un nivel alto, se supone que COMPAS ayuda a los jueces a determinar si un acusado debe permanecer en la cárcel o quedar libre mientras espera el juicio. Se entrena con los datos históricos de los acusados para encontrar correlaciones entre factores como la edad y sus antecedentes en el sistema de justicia penal, y si esa persona ha sido arrestada antes. Luego usa esas correlaciones para predecir la probabilidad de que un acusado sea detenido por un otro delito durante el período de espera del juicio (1).
Nota 1. Arrestos frente a condenas
Este proceso es muy imperfecto. Las herramientas utilizan los previos arrestos como un indicador de los delitos, pero, en realidad, hay grandes discrepancias entre ambos, porque la policía tiene un historial desproporcionado de arrestos de minorías raciales y de manipulación de datos. Además, los nuevos arrestos de reincidentes ocurren a menudo por culpa de infracciones técnicas, como no comparecer ante el tribunal, más que por la reincidencia en la actividad delictiva. Aquí lo hemos simplificado bastante para examinar lo que sucedería si los arrestos correspondieran a los delitos reales.
Esta predicción se conoce como la "puntuación de riesgo" del acusado y su objetivo es actuar a modo de recomendación: los acusados de "alto riesgo" deben ser encarcelados para evitar que causen un posible daño a la sociedad; los acusados de "bajo riesgo" deben ser puestos en libertad antes del juicio. (En realidad, los jueces no siempre siguen estas recomendaciones, pero las evaluaciones de riesgo resultan influyentes).
Sus defensores argumentan que las herramientas de evaluación de riesgo ayudan a que el sistema de justicia penal sea más justo. Sustituyen la intuición y el sesgo de los jueces, en concreto, el sesgo racial, con una evaluación aparentemente más "objetiva". También pueden reemplazar la práctica de pagar la fianza en Estados Unidos, que requiere que los acusados paguen una cantidad de dinero por su liberación. La fianza discrimina a los pobres y afecta de manera desproporcionada a los acusados negros, sobrerrepresentados en el sistema de justicia penal.
De acuerdo con la ley, COMPAS no incluye la raza en el cálculo de su puntuación de riesgo. Sin embargo, en 2016, una investigación de ProPublica reveló que, aun así, la herramienta estaba sesgada contra los negros. ProPublica descubrió que, entre los acusados que nunca volvieron a ser arrestados, los negros tenían el doble de probabilidades que los blancos de acabar en el grupo de alto riesgo de COMPAS (2).
Nota 2. Metodología de ProPublica
Para los acusados encarcelados antes del juicio, ProPublica analizó si volvieron a ser arrestados en los dos años posteriores a su liberación. Luego lo utilizó para calcular si los acusados habrían sido detenidos de nuevo antes del juicio si no hubieran sido encarcelados.
Así que nuestra tarea es intentar mejorar COMPAS. Comencemos con el mismo conjunto de datos que ProPublica utilizó en su análisis. Incluye a todos los acusados calificados por el algoritmo en el condado de Broward (EE. UU.) entre 2013 y 2014. En total, son más de 7.200 perfiles con nombre, edad, raza y la puntuación de riesgo de COMPAS, indicando si esa persona al final fue detenida de nuevo después de ser puesta en libertad o encarcelada antes del juicio.
Para facilitar la visualización de los datos, hemos muestreado aleatoriamente a 500 acusados blancos y negros del conjunto completo. Hemos representado a cada acusado como un punto.

Recuerde: todos los puntos representan a personas acusadas (pero no condenadas) de un delito. Algunas serán encarceladas antes del juicio; otras serán liberadas inmediatamente. Algunas volverán a ser arrestadas después de su liberación; otras no. Queremos comparar dos cosas: las predicciones (qué acusados recibieron la puntuación de riesgo "alta" versus "baja") y los resultados del mundo real (qué acusados realmente fueron detenidos de nuevo después de ser liberados).
COMPAS califica a los acusados en una escala del 1 al 10, donde 1 corresponde aproximadamente a un 10 % de probabilidad de volver a detenerlos, el 2 al 20 %, y así sucesivamente.
Veamos cómo COMPAS los calificó. Aunque el algoritmo solo puede ofrecer una probabilidad estadística de que un acusado sea arrestado nuevamente antes del juicio, los jueces son quienes toman la decisión definitiva: liberar o detener al acusado. Para los propósitos de este artículo, usaremos el umbral de "alto riesgo" de COMPAS, una puntuación de 7 o más, para representar la recomendación de que se detenga al acusado (3).
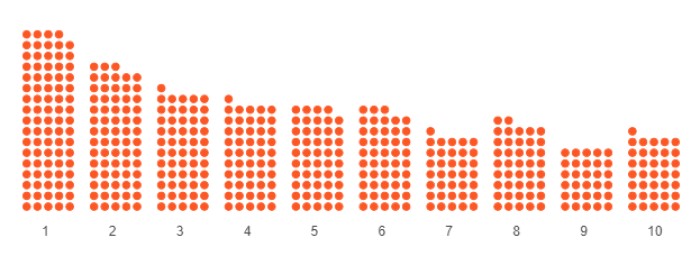
Nota 3. Puntuación de COMPAS
COMPAS fue diseñado para hacer predicciones agregadas sobre grupos de personas que comparten características similares, en vez de las predicciones sobre individuos específicos. La metodología de su puntuación y las recomendaciones sobre cómo usarla son más complicadas, pero no teníamos espacio suficiente para explicarlas; puede leer algo más sobre eso en este enlace.
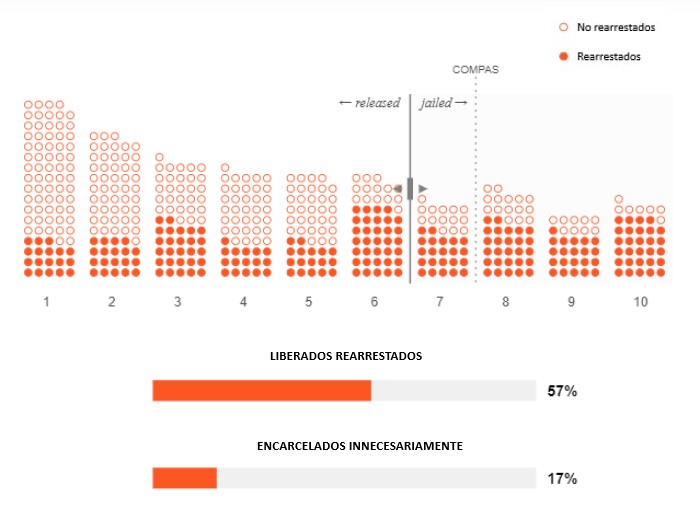
Ahora queremos rediseñar la última parte del algoritmo para encontrar un lugar más justo para el umbral de "alto riesgo". Imaginemos el mejor de los casos: todos los acusados que el algoritmo etiqueta con la puntuación de alto riesgo vuelven a ser detenidos, y todos los acusados con baja puntuación de riesgo no acaban detenidos de nuevo. A continuación, nuestro gráfico muestra cómo podría ser esta posibilidad.
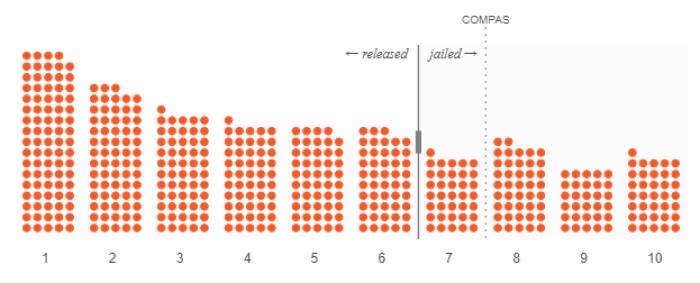
Los círculos rellenos son los acusados que fueron arrestados nuevamente; los círculos vacíos son los que no lo fueron. (En otras palabras, solo los acusados detenidos nuevamente deben ser encarcelados). Su umbral debería estar entre 6 y 7. Nadie fue detenido innecesariamente, y nadie liberado acabó arrestado de nuevo.
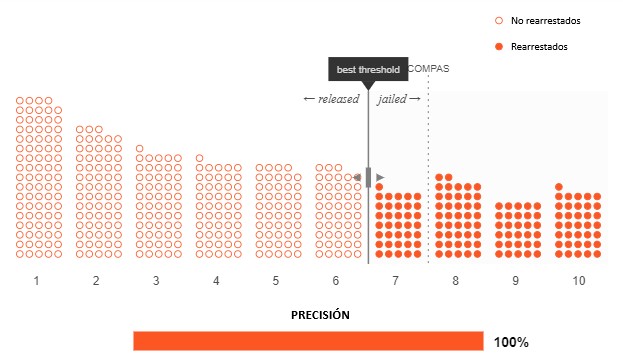
Pero, está claro que este escenario ideal nunca ocurre. Es imposible predecir perfectamente el resultado para cada persona. Esto significa que los puntos llenos y vacíos no se pueden separar tan claramente.
Aquí puede ver quién acabó arrestado de nuevo. Verá que, independientemente de dónde se coloque el umbral, nunca será perfecto: siempre encarcelaremos a algunos acusados que no acaban arrestados de nuevo (puntos vacíos a la derecha del umbral) y liberamos a algunos acusados que sí son arrestados nuevamente (puntos rellenos a la izquierda del umbral). Es un equilibrio con que el sistema de justicia penal siempre ha lidiado, así que la cosa no cambia cuando usamos un algoritmo.
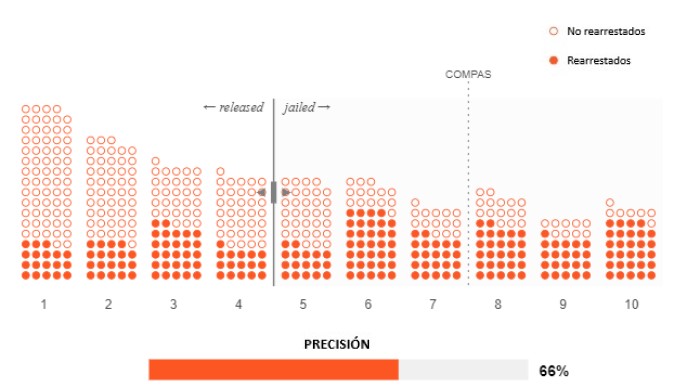
Para que resulte más claro, veamos el porcentaje de predicciones incorrectas que COMPAS hace a cada lado del umbral. Así podremos ver explícitamente si el umbral favorece a mantener a personas en la cárcel innecesariamente o liberar a personas que luego vuelven a ser arrestadas (4). El umbral predeterminado de COMPAS favorece a esto último.
Nota 4. Definiciones técnicas
Estos dos porcentajes de error también se conocen como "tasa de falsos negativos" (que hemos etiquetado como "liberados, pero arrestados nuevamente") y "tasa de falsos positivos" (que hemos etiquetado como "encarcelados innecesariamente").
¿Cómo deberíamos resolver esta situación de manera justa? No hay una respuesta universal, pero en la década de 1760, el juez inglés William Blackstone escribió: "Es mejor que diez personas culpables escapen que una inocente sufra". La proporción de Blackstone sigue teniendo una gran influencia en la actualidad. Así que usémosla como inspiración.
Ya se pueden ver dos problemas con el uso de un algoritmo como COMPAS. El primero es que una mejor predicción siempre puede ayudar a reducir las tasas de error de manera global, pero nunca puede eliminarlas por completo. Independientemente de la cantidad de datos reunidos, dos personas que parecen iguales para el algoritmo siempre pueden acabar tomando decisiones diferentes.
El segundo problema es que, incluso si se siguen las recomendaciones de COMPAS de manera constante, alguien tiene que decidir dónde poner el umbral de "alto riesgo", ya sea utilizando la proporción de Blackstone u otra medida. Eso depende de todo tipo de opiniones: políticas, económicas y sociales.
Y llegamos a un tercer problema. Aquí es donde nuestras exploraciones de la justicia comienzan a ponerse interesantes. ¿Cómo se comparan las tasas de error en diferentes grupos? ¿Hay ciertos tipos de personas que tienen más probabilidades de acabar detenidas innecesariamente? Veamos cómo son nuestros datos cuando consideramos la raza de los acusados.
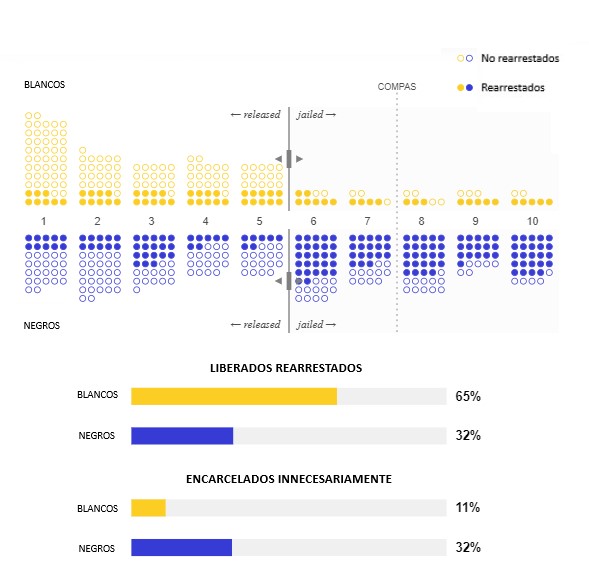
La raza es un ejemplo de una categoría protegida en Estados Unidos, lo que significa que la discriminación sobre esa base es ilegal. Otras categorías protegidas incluyen el género, la edad y la discapacidad.
Después de separar a los acusados en blancos y negros, hemos descubierto que, aunque la raza no se usa para calcular la puntuación de riesgo de COMPAS, la puntuación tiene diferentes tasas de error para ambos dos grupos. En el umbral predeterminado de COMPAS entre 7 y 8, el 16 % de los acusados negros que no son arrestados nuevamente han sido encarcelados innecesariamente, mientras que lo mismo ocurre con solo el 7 % de los acusados blancos. ¡Eso no parece nada justo! Es exactamente lo que ProPublica destacó en su investigación.
Hemos intentado volver a alcanzar la proporción de Blackstone, por lo que llegamos a la siguiente solución: los acusados blancos tienen un umbral entre 6 y 7, mientras que los acusados negros tienen un umbral entre 8 y 9. Ahora, aproximadamente el 9 % de los acusados tanto blancos como negros que no acaban detenidos nuevamente son encarcelados innecesariamente, mientras que el 75 % de los que son arrestados de nuevo después de no pasar tiempo en la cárcel. ¡Buen trabajo! Este algoritmo parece mucho más justo que el de COMPAS.
Pero ¿de verdad lo es? En el proceso de igualar las tasas de error entre razas, perdimos algo importante: nuestros umbrales para cada grupo son diferentes, por lo que nuestra puntuación de riesgo implica cosas diferentes para los acusados blancos y negros.
Los acusados blancos son encarcelados por una puntuación de riesgo de 7, pero los acusados negros con la misma puntuación son liberados. De nuevo, esto no parece justo. Dos personas con la misma puntuación de riesgo tienen la misma probabilidad de ser arrestadas de nuevo, entonces, ¿no deberían recibir el mismo trato? En EE. UU., el uso de diferentes umbrales para diferentes razas también puede plantear complicados problemas legales, según la 14ª Enmienda, la cláusula de protección de la igualdad de la Constitución.
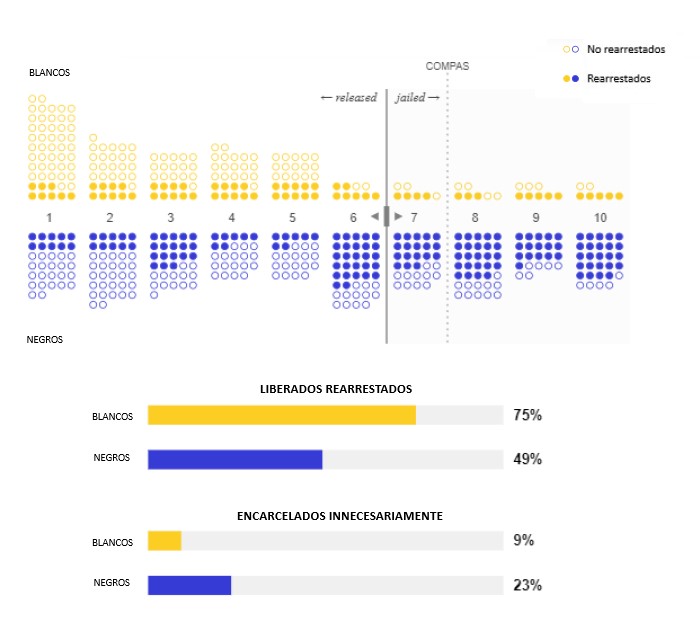
Intentemos esto una vez más con un único umbral compartido entre ambos grupos. Si se siente frustrado, es normal: no hay una solución.
Le dimos dos definiciones de la justicia: mantener las tasas de error comparables entre grupos y tratar a las personas con la misma puntuación de riesgo de igual manera. ¡Ambas definiciones son totalmente defendibles! Pero cumplir ambas al mismo tiempo es imposible.
La razón consiste en que los acusados blancos y negros vuelven a ser detenidos en niveles diferentes. Mientras que el 52 % de los acusados negros fueron arrestados de nuevo en nuestros datos del condado de Broward, ese solo fue el caso del 39 % de los acusados blancos. Existe una diferencia similar en muchas jurisdicciones en EE. UU., en parte debido a la historia del país donde la policía apuntaba desproporcionadamente a las minorías (como ya hemos mencionado antes).
Las predicciones reflejan los datos utilizados para crearlas, ya sea por algoritmo o no. Si los acusados negros acaban arrestados a una tasa más alta que los acusados blancos en el mundo real, también tendrán una tasa más alta de arrestos previstos. Esto significa que también tendrán puntuación de riesgo más alta de media, y un mayor porcentaje de ellos serán evaluados de alto riesgo, tanto correcta como incorrectamente. Esto es así independientemente del algoritmo que se utilice, siempre que esté diseñado para que cada puntuación de riesgo signifique lo mismo a pesar de la raza.
Este extraño conflicto de las definiciones de la justicia no se limita solo a los algoritmos de evaluación de riesgo del sistema de justicia penal. El mismo tipo de paradojas ocurren en los algoritmos de las calificaciones crediticias, de seguros y de contratación. En cualquier contexto en el que un sistema automatizado de toma de decisiones deba asignar recursos o castigos entre múltiples grupos que tienen diferentes resultados, las distintas definiciones de lo justo inevitablemente resultarán mutuamente excluyentes.
No existe ningún algoritmo capaz de solucionar este problema. De hecho, ni siquiera es un problema algorítmico. Los jueces están tomando actualmente el mismo tipo de decisiones forzadas, y lo han hecho a lo largo de la historia.
Pero hay algo que el algoritmo sí ha cambiado. Aunque es posible que los jueces no siempre sean transparentes sobre cómo eligen entre diferentes nociones de lo justo, las personas pueden impugnar sus decisiones. Por el contrario, COMPAS, elaborado por la empresa privada Northpointe, es un secreto comercial que no puede ser revisado ni interrogado públicamente. Los acusados ya no pueden cuestionar sus resultados y las agencias gubernamentales han perdido la capacidad de analizar el proceso de la toma de decisiones. Ya no existe la rendición pública de cuentas.
Entonces, ¿qué deberían hacer los reguladores? La Ley de Responsabilidad Algorítmica propuesta en 2019 es un ejemplo de un buen primer paso, según el profesor de derecho de la Universidad de California (EE. UU.) que es especialista en inteligencia artificial y derecho Andrew Selbst. Este proyecto de ley, que quiere regular el sesgo en los sistemas automatizados de toma de decisiones, tiene dos características destacables que sirven como modelo para la futura legislación. Primero, obligaría a las grandes empresas de tecnología a controlar sus sistemas de aprendizaje automático para detectar sesgos y discriminación en una "evaluación de impacto". En segundo lugar, no especifica la definición de lo justo.
"Con una evaluación de impacto, una empresa está siendo muy transparente sobre cómo aborda la cuestión de la justicia", afirma Selbst. Eso vuelve a introducir al debate la rendición pública de cuentas. Como "lo justo significa diferentes cosas en distintos contextos", añade Selbst, si se evita una definición específica se permite esa flexibilidad.
Pero la decisión de si los algoritmos deberían usarse para arbitrar la justicia en primer lugar es una cuestión complicada. Los algoritmos de aprendizaje automático se entrenan con "datos generados con historiales de exclusión y discriminación", escribe la profesora asociada de la Universidad de Princeton (EE. UU.) Ruha Benjamin en su libro Race After Technology. Las herramientas de evaluación de riesgo no son diferentes. La pregunta más importante sobre su uso (o del cualquier algoritmo utilizado para clasificar a las personas) es si reducen las desigualdades existentes o las agravan.
Selbst recomienda proceder con cautela: "Siempre que las nociones filosóficas de la justicia se convierten en expresiones matemáticas, pierden sus matices, su flexibilidad, su maleabilidad. Eso no quiere decir que algunas de las eficiencias de hacerlo no valgan la pena. Yo solo tengo mis dudas".
Ética
-
China contraataca a EE UU con un posible bloqueo de semiconductores
China tiene como objetivo restringir el suministro de galio y germanio, dos materiales utilizados en chips de los ordenadores y otros productos. Los expertos dicen que no tendrá el impacto deseado.

-
Los nuevos datos del mercado de Wuhan reabren el debate sobre el origen del Covid-19
Las muestras recogidas en el año 2020 han puesto de relieve el posible papel de los 'tanukis' o perros-mapache en la extensión del coronavirus desde Wuhan (China) y han provocado un melodrama entre científicos

-
La mujer que trabaja para que la tecnología alemana sea más inclusiva
Nakeema Stefflbauer consigue que las mujeres de entornos infrarrepresentados sean incluidas en la escena tecnológica de Berlín
