Pero al probar cualquier software de reconocimiento de voz recuperará la fe en la humanidad. Aunque son buenos y mejoran constantemente, estos sistemas están muy lejos de perfección. ¿Ha dicho "a ver lo" o "haberlo"? Probablemente ambos, si es una máquina con quien habla.
Así que debería reconfortar que a las máquinas aún les cueste mucho dominar el reconocimiento del habla, lo que implica que los humanos aún somos dueños de nuestro propio lenguaje.

Esa perspectiva puede que tenga que cambiar. Y rápido. El investigador de Microsoft Research Geoff Zweig y sus compañeros en Redmond (EEUU) afirman que han dominado el reconocimiento del habla y que sus algoritmos de aprendizaje de máquinas por primera vez superan el rendimiento humano en reconocer una conversación estándar.
Las investigaciones de reconocimiento del habla tienen una larga historia. Durante la década de 1950, los primeros ordenadores podían reconocer hasta 10 palabras articuladas claramente por un único locutor. Durante la década de 1980, los investigadores desarrollaron máquinas capaces de transcribir un discurso sencillo con un vocabulario de 1.000 palabras. Durante la década de 1990, avanzaron hasta grabaciones de una persona que leía The Wall Street Jou al y después hasta el habla de las noticias televisivas.
Esos escenarios son cada vez más ambiciosos. Pero también son más fáciles de asumir que el reconocimiento del lenguaje conversacional, debido a varias limitaciones. El vocabulario del Wall Street Jou al se limita a los negocios y las finanzas, y las frases están bien estructuradas y son gramaticalmente correctas, algo que no siempre pasa con el lenguaje cotidianoo. Los discursos en los informativos son algo menos formales, pero siguen estando muy estructurados y se pronuncian con precisión. Todos estos ejemplos han sido conquistados por las máquinas.
La tarea más difícil, la de transcribir el lenguaje natural del día a día, se ha resistido mucho a los esfuerzos de las máquinas.
El habla cotidiana es significativamente más difícil por el volumen del vocabulario y también por los ruidos que la gente hace al hablar. Los humanos empleamos un abanico de sonidos para gestionar las intervenciones en una conversación, un tipo de comunicación que los lingüistas denominan como los canales alte os de comunicación.
Por ejemplo, un "¿eh?" se emplea para indicar dudas al interlocutor y señalarle que debe seguir hablando. Pero "eh" es una vacilación que incida que el locutor tiene más que decir, una advertencia de que seguirá hablando. En la gestión de tu os, "¿eh?" tiene la función contraria a "eh".
A los humanos les resulta muy fácil interpretar estas interjecciones y entender su papel dentro en una conversación. Pero las máquinas siempre han luchado con ellas.
En 2000, el Instituto Nacional de Estándares y Tecnología de EEUU (NIST, por sus siglas en inglés) publicó un conjunto de datos para ayudar a los investigadores a abordar este problema. El conjunto contenía grabaciones de conversaciones entre amigos y familiares sobre cualquier tema.
La mayor parte de los datos estaban destinados a entrenar un algoritmo de aprendizaje de máquinas para reconocer el habla. El resto sirvieron como pruebas de transcripción para las máquinas.
La medida del rendimiento fue el número de palabras en las que se equivocó la máquina, y el objetivo final consistía en rendir mejor que los humanos.
Entonces, ¿cuán buenos somos los humanos? El consenso general es que cuando se trata de la transcripción, los humanos tienen una tasa de errores de aproximadamente el 4%. En otras palabras, transcriben incorrectamente cuatro palabras de cada 100. En el pasado, las máquinas no se han acercado a esa cifra ni de lejos.
Pero ahora Microsoft asegura que por fin ha igualado el rendimiento humano, aunque con una importante salvedad. Los investigadores empezaron por reevaluar el rendimiento humano en tareas de transcripción. Para ello, enviaron las grabaciones telefónicas a un servicio profesional de transcripción y midieron la tasa de errores.
Para su sorpresa, encontraron que este servicio humano tenía una tasa de errores del 5,9% para las conversaciones entre individuos sobre un tema concreto y del 11,3% para las conversaciones entre amigos y familiares. Son tasas mucho más altas de lo que se creía anteriormente.
Después, el equipo de Zweig optimizó sus propios sistemas de aprendizaje profundo basados en redes neuronales convolucionales con varios números de capas, cada una de las cuales abarca un aspecto diferente del habla. Entonces emplearon el conjunto de datos de entrenamiento para enseñar a la máquina a entender el lenguaje cotidiano y liberarlo sobre el conjunto de datos de prueba.
Los resultados: en general, el sistema de reconocimiento de voz de Microsoft tiene una tasa de error similar a la de los humanos, pero el tipo de errores que comete son bastante distintos.
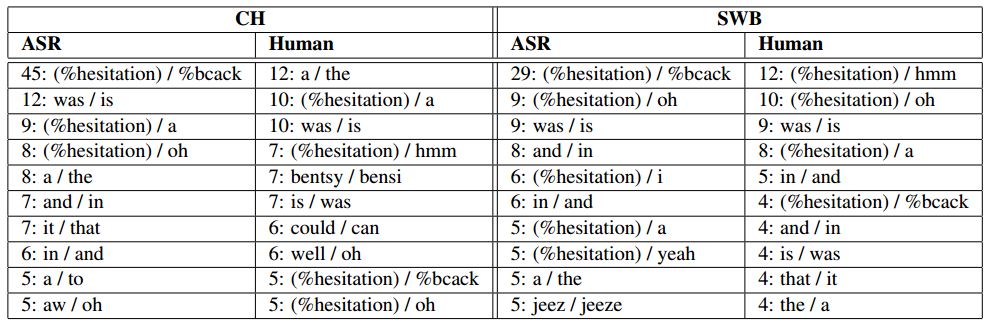
El error más frecuente que de la máquina de Microsoft es confundir las interjecciones inglesas "uh-huh" y "uh". Por el contrario, los humanos rara vez cometen ese error, pero sí tienden a confundir palabras en inglés como a (artículo indeterminado) y the ( artículo determinado) o uh (el ruido de canal alte o correspondiente a "eh" en español) y a (artículo indeterminado).
En principio no hay motivos por los que una máquina no pueda ser entrenada para reconocer interjecciones. El equipo de Zweig cree que la dificultad que sufren las máquinas con ellas probablemente tenga que ver con cómo se etiquetan dentro del conjunto de datos de entrenamiento. "El rendimiento relativamente pobre del sistema automático en esta área podría deberse simplemente a errores en las anotaciones del conjunto de datos de entrenamiento", escriben.
En general, la máquina iguala la tasa de errores humana del 5,9% para las conversaciones sobre un tema determinado pero supera el rendimiento humano en la tarea de transcribir conversaciones entre amigos y familiares con una tasa de error del 11,1%. El equipo de Zweig afirma: "Por primera vez, informamos de un rendimiento del reconocimiento automático que iguala el rendimiento humano en esta tarea".
Es un trabajo interesante. Microsoft puede haber bajado el listón al lograr esta victoria de sus máquinas, pero está claro que el futuro ya está escrito. Las máquinas están empezando a superar a los humanos en el reconocimiento del habla, y esto tendrá importantes implicaciones para la manera en la que interactuamos con las máquinas, y no tendremos que esperar demasiado para "ver lo".
Ref: arxiv.org/abs/1610.05256 : Achieving Human Parity in Conversational Speech Recognition