Cadenas de bloques y aplicaciones
Este ordenador ya sabe si has escrito un tuit bajo los efectos del alcohol
El análisis de los micromensajes bajo la embriaguez demuestra que en la ciudad se bebe más que en el campo. La investigación podría aportar más datos a este problema de salud pública
Enviar a su expareja un tuit moña a la una de la madrugada después de una botella de Chardonnay quizá no sea la mejor manera de lograr una reconciliación. Todos sabemos que el alcohol y los tuits no siempre son una buena combinación.
Aun así, un sorprendente número de nosotros caemos en esta forma peculiar de indiscreción. Y esta práctica ha dado una idea interesante a Nabil Hossain y sus compañeros de la Universidad de Rochester (EEUU).
El equipo ha entrenado a una máquina para detectar tuits escritos bajo la influencia del alcohol. Su trabajo también sirve para monitorizar las actividades relacionadas con el alcohol y la manera en que se propagan por la sociedad. Los investigadores afirman que el método podría tener un importante impacto sobre la manera de entender y responder a los problemas de salud pública que genera la ingesta del alcohol y otras actividades.
El trabajo del equipo de Hossain está basado en dos avances. El primero consiste en una manera de entrenar un algoritmo de aprendizaje de máquinas para reconocer tuits relacionados con el alcohol y los que son escritos bajo sus efectos. El segundo es una manera de identificar la localización del domicilio del usuario de Twitter con una precisión mucho mayor de la que ha sido posible anteriormente y, por tanto, determinar si está bebiendo en casa o no.
El equipo empezó por recopilar micromensajes geolocalizados enviados entre enero y julio de 2014 desde la ciudad de Nueva York y desde el Condado de Monroe (ambas en EEUU), que incluye la ciudad de Rochester. A partir de este conjunto de datos, filtraron todos los tuits que mencionan el alcohol o palabras relacionadas con el alcohol como borracho, cerveza, fiesta y así sucesivamente.
Para analizar los tuits, recurrieron a los trabajadores del servicio de crowdsourcing Mechanical Turk de Amazon. Para cada tuit, pidieron a tres turkeros que determinaran si el mensaje se refería al alcohol y en caso afirmativo, si hacía referencia al consumo de alcohol por parte del tuitero. Finalmente, preguntaron si el tuit fue enviado al mismo tiempo que el tuitero bebía.

Ese proceso incluyó unos 11.000 tuits geolocalizados asociados con el alcohol (aunque los detalles acerca del tamaño de este estudio, y por tanto su relevancia, desafortunadamente brillan por su ausencia en el trabajo). Es un conjunto de datos lo suficientemente grande para entrenar un algoritmo de aprendizaje de máquinas para detectar tuits relacionados con el alcohol por su propia cuenta.
Eso les llevó a la siguiente pregunta: ¿dónde suele estar la gente mientras tuitean acerca de beber? Y, concretamente: ¿están en casa o en otro lugar?
Los investigadores han divisado varios métodos para averiguar la ubicación del domicilio de las personas sólo con el uso de sus tuits geolocalizados. Estos incluyen elegir la ubicación desde la que tuitean con mayor frecuencia, elegir el sitio desde donde envían el último tuit del día o el lugar desde el que tuitean entre la una y las seis de la madrugada. Sin embargo, todos estos métodos tienen debilidades que hacen que resulte difícil depender de ellos.
El equipo de Hossain desarrolló otro enfoque. Elaboraró una lista de palabras y frases con altas probabilidades de pertenecer a tuits que se escriben desde casa como "¡Por fin en casa!" o bañera, sofá, tele y así sucesivamente. Filtraron los tuits geolocalizados que contenían alguna de estas palabras y preguntaron a tres turkeros si creían que cada tuit se había enviado desde casa o no, guardando sólo los tuits que suscitaron una respuesta afirmativa de los tres.
El equipo de Hossain designó estos tuits como un conjunto de datos de verificación del terreno para la localización del domicilio y lo empleó para entrenar un algoritmo de aprendizaje de máquinas para identificar otros patrones asociados con los tuits elaborados desde casa. El algoritmo examinó cómo la localización del domicilio corresponde con otros indicadores como la localización del último tuit del día, la localización más popular de un tuit, el porcentaje de tuits con una determinada localización y así sucesivamente.
Depender de varios indicadores para determinar la localización del domicilio mejora bastante la precisión del enfoque, en comparación con los que emplean un sólo indicador. De hecho, el equipo de Hossain afirma poder determinar la localización del domicilio con un margen de 100 metros y con una precisión de hasta el 80%. Es significativamente mejor que trabajos anteriores.
Juntas, estas dos técnicas permitieron al equipo averiguar cuándo y dónde bebe la gente. Y emplearon esta información para comparar los patrones del consumo de alcohol de la ciudad de Nueva York y la zona más rural del Condado de Monroe.
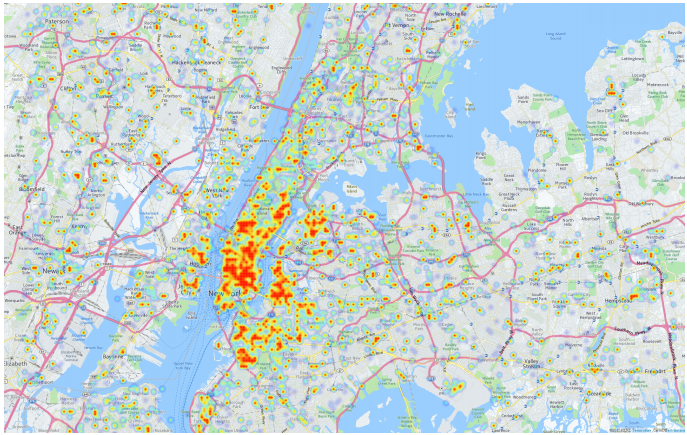
Lo consiguen al dividir cada zona en cuadrículas de 10.000 metros cuadrados y marcar las zonas donde existan tuits asociados con el alcohol. Eso les permite elaborar y comparar "mapas de calor" del consumo de alcohol para cada zona.
También distinguen entre tuits sobre beber enviados desde el domicilio y los escritos desde otra parte. Y mapean los distribuidores que venden alcohol en cada zona. Eso permite investigar la relación entre la densidad de tuits enviados desde distintas zonas en estado de embriaguez y la densidad de los puntos de venta de alcohol.
Los resultados representan una lectura interesante. Primero, el equipo de Hossain señala que, en proporción, hay más tuits ebrios que proceden de Nueva York que desde el Condado de Monroe. "Una posible explicación sería que una ciudad tan poblada como la de Nueva York, con una gran densidad de puntos de venta de alcohol y mucha gente haciendo vida social, tiene mayores probabilidades de disponer de una tasa más alta de consumo de alcohol", describe la investigación.
Es más, los datos de geolocalización revelan que en Nueva York la gente tiende a beber más en casa (o dentro de un radio de 100 metros desde su casa) que en el Condado de Monroe, donde una alta proporción de gente bebe a más de un kilómetro de distancia de sus casas.
Los mapas de calor también revelan patrones interesantes. Permiten al equipo centrarse en las cuadrículas donde se hayan enviado al menos cinco tuits sobre alcohol. "Creemos que tales cuadrículas representan regiones de actividades de consumo inusuales", escribe el equipo de Hossain.
También descubrieron una correlación entre la densidad de puntos de venta de alcohol en una determinada zona y el número de tuits que indican que alguien está bebiendo en ese momento. Eso suscita una pregunta interesante acerca de cómo la correlación y la causalidad están vinculados en este caso. ¿Provoca una alta densidad de puntos de venta de alcohol que la gente beba más? ¿O se congregan los bebedores en zonas con una alta densidad de puntos de venta de alcohol? Por supuesto, este tipo de datos por sí solos no podrá contestar a estas preguntas.
No obstante, la gran potencia de esta técnica reside en que es barata y rápida. En contraste, conseguir datos parecidos sobre los patrones del consumo de alcohol por otros medios resulta extremadamente caro y complicado.
Normalmente, requeriría que la gente sea cuidadosamente elegida para rellenar cuestionarios y que sus respuestas sean analizadas en detalle. El enfoque de aprendizaje de máquinas podría hasta monitorizar esta actividad en tiempo real. El equipo asegura: "Nuestros resultados demuestran que los tuits pueden proporcionar unas potentes y detalladas pistas acerca de las actividades que se realizan dentro de una ciudad".
Existen salvedades, claro. Existe un claro sesgo en los datos recopilados de Twitter puesto que la gente joven y determinadas minorías están sobrerrepresentadas. Pero otros métodos de recopilación de datos tienen sesgos similares. Por ejemplo, las encuestas tienden a infrarrepresentar a la gente que no quiere rellenar cuestionarios, como algunos inmigrantes. Identificar y lidiar con los sesgos es una parte importante de todos los métodos de recopilación de datos.
El equipo de Hossain tiene grandes planes para su técnica. En el futuro, quieren estudiar cómo el consumo de alcohol varía en función de la edad, el sexo, la etnia, y así sucesivamente; cómo diferentes entornos influencian los tuits ebrios, por ejemplo las casas de amigos, los estadios, parques y así sucesivamente; y comparar el ritmo al que los bebedores entran y salen de barrios colindantes.
El aspecto social de Twitter resultará útil también. Hossain afirma: "Podemos explorar la red social de los bebedores para averiguar cómo las interacciones y presiones sociales dentro de las redes sociales influencian la tendencia de referirse a la bebida".
Todo eso podría ayudar a informar el debate acerca de los aspectos del alcohol relacionados con la salud, que representan la tercera causa de muertes evitables en Estados Unidos. Son 75.000 muertes que provoca el alcohol al año, una cifra que coloca la relevancia de este trabajo en perspectiva en comparación con los altibajos de nuestras vidas amorosas.
Ref: arxiv.org/abs/1603.03181: Inferring Fine-grained Details on User Activities and Home Location from Social Media: Detecting Drinking-While-Tweeting Patterns in Communities
Cadenas de bloques y aplicaciones
Qué significa estar constantemente contectados unos a otros y disponer de inmensas cantidades de información al instante.
-
Ciberguerra, 'ransomware' y robo de criptodivisas: la claves en ciberseguridad para 2023
"Cuando se trata de eliminar el 'ransomware' desde la fuente, creo que dimos un paso atrás", asegura un experto

-
Descentralización contra regulación: el debate de las criptomonedas en 2023
Este año habrá una lucha por el alma de las finanzas descentralizadas

-
Ethereum abandona la criptominería y adopta la prueba de participación
Nadie sabe exactamente qué le depara a la industria de las criptomonedas tras esta esperada actualización
