
Cadenas de bloques y aplicaciones
Historia completa de cómo Facebook se volvió adicto a la desinformación
La máxima principal para todos los trabajadores de la red social consiste en aumentar el crecimiento y la participación, aunque eso signifique difundir odio, teorías de la conspiración y extremismo. Su director de IA, Joaquin Quiñonero, creó los algoritmos que lo consiguieron y ahora no sabe cómo arreglar el problema
El director de Inteligencia Artificial (IA) en Facebook, Joaquín Quiñonero Candela, pidió disculpas al público. Era el 23 de marzo de 2018, pocos días después de que saliera a la luz el escándalo de Cambridge Analytica, la consultora que había trabajado en la campaña de las elecciones presidenciales de EE. UU. de 2016 de Donald Trump y extraído subrepticiamente los datos personales de decenas de millones de estadounidenses de sus cuentas de Facebook en un intento de influir en sus votos.
Fue la mayor violación de privacidad en la historia de Facebook, pero la charla que Quiñonero iba a dar en una conferencia sobre, entre otras cosas, "la intersección de la inteligencia artificial, la ética y la privacidad" en la empresa, se había planificado con antelación. El responsable pensó en cancelar su participación, pero después de hablarlo con su director de Comunicación, mantuvo su compromiso.
Cuando subió al escenario de la sala, empezó con una confesión: "Acabo de vivir los cinco días más difíciles de mi trabajo en Facebook. Si hay críticas, las aceptaré".
El escándalo de Cambridge Analytica inició la mayor crisis publicitaria de Facebook. Aumentó los temores de que los algoritmos que determinan lo que la gente ve en la plataforma estuvieran amplificando las noticias falsas y el odio, y que los hackers rusos los habían utilizado para intentar influir en las elecciones a favor de Trump. Millones de usuarios comenzaron a eliminar la aplicación; algunos empleados se fueron de la empresa en señal de protesta; la capitalización de mercado de la compañía se desplomó en más de 100.000 millones de dólares (84.041 millones de euros) después de su comunicado sobre las ganancias de julio.
En los meses siguientes, Mark Zuckerberg, también empezó a disculparse por no haber tenido "una visión lo suficientemente amplia" de las responsabilidades de Facebook y por sus errores como CEO. Internamente, la directora de Operaciones, Sheryl Sandberg, inició una auditoría de derechos civiles de dos años para recomendar formas en las que la empresa podría evitar el uso de su plataforma para socavar la democracia.
Finalmente, el director de Tecnología de Facebook, Mike Schroepfer, pidió a Quiñonero que creara un equipo con una finalidad un poco ambigua: examinar el impacto social de los algoritmos de la empresa. El grupo se denominó a sí mismo Society and AI Lab (SAIL) y el año pasado se fusionó con otro equipo que trabajaba en las cuestiones de privacidad de datos para formar Responsible AI.
Quiñonero fue una selección natural para ese trabajo. Él, más que nadie, fue el responsable de la posición de Facebook como potencia en IA. En sus seis años en Facebook, Quiñonero había creado algunos de los primeros algoritmos para mostrar a los usuarios el contenido adaptado con precisión a sus intereses, y luego difundió esos algoritmos por toda la empresa. Ahora, su misión era hacerlos menos dañinos.
Facebook ha señalado constantemente los esfuerzos de Quiñonero y otros como vía para reparar su reputación. Regularmente saca a la luz a varios líderes para hablar con medios de comunicación sobre las reformas en curso. En mayo de 2019, otorgó una serie de entrevistas con Schroepfer al The New York Times, que premió a la compañía humanizando a un ejecutivo sensible y bien intencionado que se esfuerza por superar los desafíos técnicos de filtrar la desinformación y el discurso de odio de un flujo de contenido que ascendía a miles de millones de publicaciones al día. The New York Times escribió que estos desafíos eran tan difíciles que Schroepfer llegaba a emocionarse: "A veces se le saltan las lágrimas por eso".
En la primavera de 2020, aparentemente me tocó a mí. El director de Comunicación de IA de Facebook, Ari Entin, me preguntó si quería echar un vistazo al trabajo de IA de la empresa. Después de hablar con varios de sus líderes de IA, decidí centrarme en Quiñonero. Entin nos puso en contacto, encantado. Quiñonero era una buena opción para servir de protagonista no solo por ser líder del equipo de Responsible AI, sino también porque había convertido a Facebook en una empresa impulsada por la IA.
Quiñonero también me pareció una elección natural para escribir sobre este tema. En los años transcurridos desde que formó su equipo tras el escándalo de Cambridge Analytica, las preocupaciones sobre la propagación de mentiras y odio en Facebook solo aumentaban. A finales de 2018, la empresa admitió que esta actividad había contribuido a impulsar una campaña genocida antimusulmana durante varios años en Myanmar (anteriormente Birmania).
En 2020, ya bastante tarde, Facebook comenzó a tomar medidas contra los negacionistas del Holocausto, los antivacunas y la teoría de la conspiración QAnon. Todas estas peligrosas mentiras proliferaban gracias a las capacidades de la inteligencia artificial que Quiñonero había ayudado a construir. Los algoritmos que sustentan el negocio de Facebook no fueron creados para filtrar el contenido falso o incendiario; sino para que las personas compartan y se involucren con la mayor cantidad de contenido posible mostrándoles cosas que probablemente les escandalizarían o las estimularían. Solucionar este problema me parecía el terreno central de Responsible AI.
Comencé a realizar videollamadas a Quiñonero con regularidad. También hablé con los directivos de Facebook, empleados actuales y antiguos, expertos de la industria y otros externos. Muchos solo aceptaron hablar bajo la condición de anonimato porque habían firmado acuerdos de confidencialidad o temían represalias. Yo quería saber: ¿Qué hacía el equipo de Quiñonero para frenar el odio y las mentiras en su plataforma?

Foto: Joaquín Quiñonero Candela frente a su casa en el Área de la Bahía (EE. UU.), donde vive con su esposa y sus tres hijos. Créditos: Winni Wintermeyer
Pero Entin y Quiñonero tenían diferentes actitudes. Cada vez que yo intentaba mencionar estos temas, mis solicitudes eran descartadas o redirigidas. Solo querían hablar del plan del equipo de Responsible AI para abordar un problema específico: el sesgo de la IA, con el que los algoritmos discriminan a algunos grupos concretos de usuarios. Un ejemplo sería un algoritmo de targeting de anuncios que muestre determinadas oportunidades laborales o de vivienda a los blancos y no a las minorías.
Pero cuando miles de manifestantes irrumpieron en el Capitolio de Estados Unidos en enero, organizados en parte a través de Facebook y motivados por las mentiras sobre las elecciones robadas que se habían extendido por toda la plataforma, se notaba claramente de mis conversaciones que el equipo de Responsible AI no había logrado avanzar contra la desinformación ni la incitación al odio porque nunca había tenido esos problemas como foco principal. Y lo que era aún más importante, me di cuenta de que si el equipo lo fuera a intentar, se enfrentaría a un fracaso seguro.
La razón es simple. Todo lo que la empresa lleva a cabo y decide no hacer surge de una única motivación: el incansable deseo de crecimiento de Zuckerberg. Los conocimientos de IA de Quiñonero sobrealimentaron ese crecimiento. Aprendí en mi investigación que su equipo se ha limitado a solucionar el sesgo de la IA porque prevenirlo ayuda a la empresa a evitar la regulación propuesta que, si se aprueba, podría obstaculizar ese crecimiento. Los directivos de Facebook también han debilitado o detenido en repetidas ocasiones muchas iniciativas para limpiar la desinformación en la plataforma porque al hacerlo, su crecimiento acabaría perjudicado.
En otras palabras, el trabajo del equipo de Responsible AI, cualesquiera que sean sus méritos en el problema específico de abordar el sesgo de la IA, es esencialmente irrelevante para solucionar los problemas más importantes de la desinformación, el extremismo y la polarización política. Y todos nosotros pagamos el precio.
"En el negocio de maximizar la participación, no existe el interés en la verdad. No interesa el daño, la división, la conspiración. De hecho, son bienvenidos. Siempre hacen lo mínimo para poder publicar su comunicado de prensa. Pero salvo algunas excepciones, no creo que eso se traduzca en mejores políticas. En realidad, nunca lidian con los problemas fundamentales", asegura la profesora de la Universidad de California en Berkeley (EE. UU.) Hany Farid, que colabora con Facebook para comprender la desinformación basada en imágenes y vídeos en la plataforma.
En marzo de 2012, Quiñonero visitó a un amigo en el Área de la Bahía (EE. UU.). En aquel entonces, Quiñonero era director de la oficina de Microsoft Research en Reino Unido, y dirigía un equipo que usaba el aprendizaje automático para conseguir que más visitantes hicieran clic en los anuncios mostrados por el motor de búsqueda de la empresa, Bing. Quiñonero tenía poca experiencia y el equipo se había formado hacía menos de un año. El aprendizaje automático, la rama de la inteligencia artificial, aún tenía que comprobarse como solución a los problemas de la industria a gran escala. Pocos gigantes tecnológicos habían invertido en esa tecnología.
El amigo de Quiñonero quiso presumir de su nuevo empleador, una de las start-ups más populares de Silicon Valley: Facebook, que entonces tenía ocho años y que ya contaba con cerca de 1.000 millones de usuarios activos mensuales (es decir, aquellos que habían iniciado sesión al menos una vez en los últimos 30 días). Mientras Quiñonero paseaba por la sede, vio a un ingeniero realizar una actualización importante en el sitio web, algo que habría implicado una gran burocracia en Microsoft. Fue una introducción memorable a la filosofía de Zuckerberg: "Muévete rápido y rompe cosas". Quiñonero estaba asombrado por las posibilidades. En una semana, había pasado varias entrevistas y firmó una oferta para unirse a la empresa.
Su llegada no pudo haber sido en un momento mejor. El servicio de anuncios de Facebook se encontraba en medio de una rápida expansión mientras la compañía se preparaba para su OPI de mayo. El objetivo era aumentar los ingresos y enfrentarse a Google, que tenía la mayor parte del mercado de la publicidad online. El aprendizaje automático, capaz de predecir qué anuncios irían mejor con qué usuarios y, por lo tanto, de volverlos más efectivos, podía ser la herramienta perfecta. Poco después de empezar, Quiñonero fue ascendido para dirigir un equipo similar al que había dirigido en Microsoft.

Foto: Quiñonero comenzó a criar pollos a finales de 2019 como forma de relajarse de la intensidad de su trabajo. Créditos: Winni Wintermeyer.
A diferencia de los algoritmos tradicionales, codificados por ingenieros, los algoritmos de aprendizaje automático se "entrenan" en los datos introducidos para aprender las correlaciones entre ellos. El algoritmo entrenado, conocido como modelo de aprendizaje automático, puede automatizar las futuras decisiones. Un algoritmo entrenado con datos de los clics en los anuncios, por ejemplo, podría aprender que las mujeres hacen clic en los anuncios de leggings de yoga con más frecuencia que los hombres. El modelo resultante luego mostrará más de esos anuncios a las mujeres. En la actualidad, en una empresa basada en inteligencia artificial como Facebook, los ingenieros generan innumerables modelos con ligeras variaciones para ver cuál funciona mejor en un problema determinado.
La enorme cantidad de datos de los usuarios de Facebook dio a Quiñonero una gran ventaja. Su equipo pudo desarrollar modelos capaces de aprender a deducir la existencia no solo de las categorías amplias como "mujeres" y "hombres", sino de las más detalladas como "las mujeres de entre 25 y 34 años a las que les gustaban las páginas de Facebook relacionadas con el yoga" y mostrarles anuncios específicos. Cuanto más detallada sea la segmentación o microtargeting, mayores serán las posibilidades de clic, lo que daría a los anunciantes un mayor rendimiento por su inversión.
En un año, el equipo de Quiñonero había desarrollado estos modelos, así como las herramientas para diseñar e implementar más rápidamente otros nuevos. Antes, los ingenieros de Quiñonero tardaban entre seis y ocho semanas en construir, entrenar y probar un nuevo modelo. En la actualidad, lo hacen todo en una semana.
La noticia del éxito se expandió rápidamente. El equipo que trabajaba en determinar qué publicaciones verían los usuarios individuales de Facebook en su sección de noticias personales quería aplicar las mismas técnicas. Igual que los algoritmos se podían entrenar para predecir quién haría clic en qué anuncio, también podían hacer lo mismo para predecir a quién le gustaría o compartiría qué publicación, y luego se daría más importancia a esas publicaciones. Si el modelo determinaba que a una persona le gustan mucho los perros, por ejemplo, las publicaciones de sus amigos sobre perros aparecerían más arriba en la sección de noticias de ese usuario.
El éxito de Quiñonero con la sección de noticias, junto con la nueva e impresionante investigación sobre la inteligencia artificial que se llevaba a cabo fuera de la empresa, llamó la atención de Zuckerberg y Schroepfer. Facebook ya tenía algo más de 1.000 millones de usuarios, lo que la hacía más de ocho veces mayor que cualquier otra red social, pero sus directivos querían saber cómo seguir creciendo. Los ejecutivos decidieron invertir en inteligencia artificial, en la conectividad a internet y en la realidad virtual.
Por eso crearon dos equipos de IA. Uno era FAIR, el laboratorio de investigación básica para avanzar en las capacidades de la última tecnología. El otro, Applied Machine Learning (AML), integraría esas capacidades en productos y servicios de Facebook. En diciembre de 2013, tras varios meses de cortejo y persuasión, los directivos reclutaron para liderar FAIR a uno de los nombres más importantes del campo, Yann LeCun. Tres meses más tarde, Quiñonero fue ascendido de nuevo, esta vez para dirigir AML. (Luego pasó a llamarse FAIAR, pronunciado igual que "fuego" en inglés).
"Así es como se sabe lo que tiene en mente. Durante un par de años, yo siempre estaba a unos pasos del escritorio de Mark", Joaquín Quiñonero Candela.
En su nuevo puesto, Quiñonero construyó una nueva plataforma de desarrollo de modelos a la que cualquiera de Facebook podía acceder. Denominada FBLearner Flow, permitía a los ingenieros con poca experiencia en IA entrenar e implementar distintos modelos de aprendizaje automático en unos días. A mediados de 2016, la usaba más de una cuarta parte del equipo de ingeniería de Facebook y ya se había utilizado para entrenar a más de un millón de modelos, incluidos los de reconocimiento de imágenes, la segmentación de anuncios y la moderación de contenido.
La obsesión de Zuckerberg por convertir a todo el mundo en usuario de Facebook había encontrado una nueva y poderosa arma. Los equipos ya habían usado diferentes tácticas de diseño, como experimentar con el contenido y la frecuencia de las notificaciones, para intentar enganchar a los usuarios de manera más efectiva. Su objetivo, entre otras cosas, era aumentar la métrica llamada L6 / 7, la fracción de personas que iniciaron sesión en Facebook en seis de los siete días anteriores.
L6 / 7 es solo una de las innumerables formas en las que Facebook ha medido la "participación": la predisposición de las personas a usar su plataforma de cualquier manera, ya sea publicando algo, comentando las publicaciones, dándole a Me gusta o compartiéndolas, o solo mirándolas. Cada interacción del usuario que antes era analizada por ingenieros, ahora se analizaba mediante algoritmos. Esos algoritmos creaban bucles de retroalimentación mucho más rápidos y personalizados para ajustar y adaptar el servicio de noticias de cada usuario para seguir aumentando las cifras de participación.
Zuckerberg, cuya oficina estaba en el centro del Edificio 20, la torre principal de la sede de Menlo Park, colocó a los nuevos equipos FAIR y AML a su lado. Muchos de los primeros empleados de IA estaban tan cerca que su escritorio prácticamente tocaba el de Zuckerberg. Era "el santuario interior", resalta un exlíder de la organización de inteligencia artificial (la parte de Facebook que contiene todos sus equipos de inteligencia artificial), que recuerda al CEO alejando o acercando a la gente de él a medida que ganaban o perdían su confianza. Quiñonero confirma: "Así es como se sabe lo que tiene en mente. Durante un par de años, yo siempre estaba a unos pasos del escritorio de Mark".
Con los nuevos modelos de aprendizaje automático que salían online todos los días, la empresa creó un nuevo sistema para seguir su impacto y maximizar la participación de los usuarios. El proceso sigue siendo todavía el mismo hoy en día. Los equipos entrenan un nuevo modelo de aprendizaje automático en FBLearner, ya sea para cambiar el orden de la clasificación de las publicaciones o para captar mejor el contenido que viola las normas de la comunidad de Facebook (sus reglas sobre lo que está permitido en la plataforma y lo que no). Luego, prueban el nuevo modelo en un pequeño subconjunto de usuarios de Facebook para medir cómo cambian las métricas de participación, como la cantidad de Me gusta, comentarios y las veces en las que se comparten las publicaciones, explica el antiguo director de Ingeniería para la sección de noticias de 2016 a 2018, Krishna Gade.
Si un modelo reduce demasiado la participación, acaba descartado. De lo contrario, se implementa y se monitoriza continuamente. Gade explicó en Twitter que sus ingenieros recibían notificaciones cada pocos días, cuando bajaban métricas como el número de Me gusta o comentarios. Luego descifraban qué había causado el problema y si algún modelo tenía que volver a entrenarse.
Pero este enfoque pronto causó otros problemas. Los modelos que maximizan la participación también favorecen la controversia, la desinformación y el extremismo: en pocas palabras, a la gente le gustan las cosas escandalosas. A veces, esto enciende las tensiones políticas existentes. Por ahora, el ejemplo más devastador es el caso de Myanmar (antes Birmania), donde las noticias falsas virales y el discurso de odio sobre la minoría musulmana rohingya llevaron el conflicto religioso del país a un genocidio en toda regla. Facebook admitió en 2018, después de años de restar importancia a su papel, que no había hecho lo suficiente "para ayudar a evitar que nuestra plataforma se utilice para fomentar la división e incitar a la violencia offline".
Si bien al principio Facebook pudo haber sido ajeno a estas consecuencias, las analizaba en 2016. En una presentación interna de ese año, publicada por el Wall Street Journal, la investigadora de la empresa Monica Lee descubrió que Facebook no solo albergaba gran cantidad de grupos extremistas, sino que también los promocionaba entre sus usuarios: "El 64 % de todas las adhesiones a grupos extremistas se deben a nuestras herramientas de recomendación", explicaba la presentación, principalmente gracias a los modelos detrás de las funciones "Grupos a los que podrías unirte" y "Descubrir".
"La pregunta para los directivos era: ¿Deberíamos optimizar la participación si descubrimos que alguien se encuentra en un estado mental vulnerable?", antiguo investigador de IA que se incorporó en 2018.
En 2017, el veterano director de Productos de Facebook, Chris Cox, formó un nuevo grupo de trabajo para analizar si maximizar la participación de los usuarios en Facebook contribuía a la polarización política. Encontró que, efectivamente, había una correlación y que la reducción de la polarización tendría un impacto en la participación. En un documento de mediados de 2018 publicado por Journal, el grupo propuso varias posibles soluciones, como ajustar los algoritmos de recomendación para sugerir una serie más diversa de grupos a los que los usuarios se podrían unir. Pero también reconoció que algunas de esas ideas eran "anticrecimiento". La mayoría de las propuestas no siguieron adelante y el grupo de trabajo se disolvió.
Desde entonces, otros empleados han corroborado estos hallazgos. Un antiguo investigador de inteligencia artificial de Facebook que se unió en 2018 asegura que su equipo y él realizaban "estudio tras estudio" confirmando la misma idea fundamental: los modelos que maximizan la participación aumentan la polarización. Podían rastrear fácilmente la medida en la que los usuarios estaban de acuerdo o en desacuerdo en diferentes temas, con qué contenido les gustaba interactuar y cómo cambiaban sus posturas como consecuencia. Independientemente del tema, los modelos aprendían a alimentar a los usuarios con las visiones cada vez más extremas. "Con el tiempo, se vuelven más polarizados de una manera medible", afirma.
El equipo de este investigador también descubrió que los usuarios con tendencia a publicar contenido melancólico o interactuar con él (un posible signo de depresión), podrían fácilmente pasar a buscar contenido cada vez más negativo, lo que podría empeorar aún más su salud mental. El equipo propuso ajustar los modelos de clasificación de contenido para que dejaran de maximizar solo la participación en el caso de estos usuarios y se les mostraran menos publicaciones deprimentes. "La pregunta para los directivos era: ¿Deberíamos optimizar la participación si descubrimos que alguien se encuentra en un estado mental vulnerable?", recuerda el investigador. (Una portavoz de Facebook respondió que no había podido encontrar documentación relacionada con esta propuesta).
Pero cualquier cosa que redujera la participación, incluso por razones como no agravar la depresión de un usuario, provocaba muchas dudas entre los líderes. Teniendo en cuenta que las evaluaciones de desempeño y los salarios de los empleados estaban vinculados al éxito de los proyectos, los propios empleados aprendieron rápidamente a descartar proyectos que recibían ese rechazo y continuar trabajando en los que se imponían desde arriba.
Uno de estos proyectos más impulsados por los líderes de la empresa implicó predecir si un usuario podría estar en peligro por algo que varias personas ya habían hecho: transmitir en vivo su propio suicidio en Facebook Live. La tarea consistió en construir un modelo para analizar los comentarios que otros usuarios escribían en un vídeo después de que se publicara en directo, y que los usuarios en riesgo se podían comunicar con los revisores formados de la comunidad de Facebook que podían llamar a los servicios de emergencia locales para controlar su estado mental. No requería ningún cambio en los modelos de clasificación de contenido, tenía un impacto insignificante en la participación y desviaba de manera efectiva la prensa negativa. También era casi imposible de llevar a cabo, explica el investigador: "Era más bien un truco de relaciones públicas. La eficacia de intentar determinar si alguien se suicidará en los próximos 30 segundos, basándose en los primeros 10 segundos de análisis de un vídeo, no era muy buena".
Facebook discrepa con esta opinión y señala que el equipo que trabajó en este esfuerzo predijo con éxito qué usuarios estaban en riesgo y aumentó la cantidad de controles de estado mental realizados. Pero la empresa no ha publicado los datos sobre la precisión de sus predicciones ni cuántos controles de estado mental resultaron ser verdaderas emergencias.
Por otro lado, ese antiguo empleado no deja que su hija use Facebook.
Quiñonero tenía que estar perfectamente preparado para abordar estos problemas cuando creó el equipo SAIL (más tarde Responsible AI) en abril de 2018. Durante el tiempo que pasó como el director de AML se había familiarizado con los algoritmos de la empresa, especialmente con los que se utilizaban para recomendar las publicaciones, anuncios y otro contenido para los usuarios.
También parecía que Facebook estaba dispuesto a tomarse estos problemas en serio. Mientras que los esfuerzos anteriores se habían dispersado por toda la empresa, en ese momento Quiñonero fue dotado de un equipo centralizado con libertad de acción para trabajar en lo que considerara conveniente en la intersección de la IA y la sociedad.
En aquel entonces, Quiñonero estudiaba por su cuenta cómo ser un tecnólogo responsable. El campo de la investigación de la IA prestaba cada vez más atención a los problemas del sesgo de la IA y la responsabilidad a raíz de los importantes estudios que mostraban que, por ejemplo, un algoritmo calificaba a los acusados negros como más propensos a ser arrestados que a los acusados blancos que habían sido arrestados por el mismo delito o por uno más grave. Quiñonero empezó a estudiar la literatura científica sobre la equidad algorítmica, leyó libros sobre la ingeniería ética y la historia de la tecnología y habló con expertos en derechos civiles y filósofos de la moral.
Durante las muchas horas que hablé con él, me di cuenta de que Quiñonero se tomaba este tema en serio. Se había unido a Facebook en medio de la Primavera Árabe, la serie de revoluciones contra los regímenes opresivos del Oriente Medio. Los expertos elogiaron las redes sociales por difundir la información que provocó los levantamientos y por brindar a las personas herramientas para organizarse. Quiñonero, que nació en España, pero fue criado en Marruecos, donde experimentó de primera mano la supresión de la libertad de expresión, sentía una intensa conexión con el potencial de Facebook como una fuerza para el bien.
Seis años más tarde, Cambridge Analytica amenazó con anular esta promesa. La controversia obligó a Quiñonero a confrontar su fe en la empresa y analizar qué significaría para su integridad el seguir siendo parte de ella. Quiñonero sostiene: "Creo que lo que le sucede a la mayoría de las personas que trabajan en Facebook, y definitivamente ha sido mi caso, es que no hay límite entre Facebook y yo. Es extremadamente personal". Finalmente decidió quedarse y dirigir SAIL porque creía que podía hacer más por el mundo ayudando a cambiar la empresa que dejándola.
El viejo amigo de Quiñonero y uno de los líderes del equipo de Google Brain, Zoubin Ghahramani, detalla: "Creo que, si alguien está en una empresa como Facebook, especialmente en los últimos años, realmente se puede dar cuenta del impacto que tienen sus productos en la vida de las personas, en lo que piensan, en cómo se comunican, en cómo interactúan entre sí. Sé que Joaquín se preocupa profundamente por todos los aspectos de eso. Como alguien que se esfuerza por lograr mejores cosas y perfeccionarlas, él conoce el importante papel que puede tener en la creación tanto del pensamiento como de las políticas en torno a la IA responsable".
Al principio, SAIL contaba con solo cinco personas de diferentes partes de la empresa, pero todas estaban interesadas en el impacto social de los algoritmos. La fundadora y científica investigadora del equipo Central de Ciencia de datos de la empresa, Isabel Kloumann, trajo consigo la versión inicial de la herramienta para medir el sesgo en los modelos de IA.
El equipo también aportó muchas otras ideas para proyectos. El antiguo líder de la organización de IA, que estuvo presente en algunas de las primeras reuniones de SAIL, recuerda una propuesta para combatir la polarización, que supuso el uso del análisis de sentimientos (una forma de aprendizaje automático que interpreta la opinión en los fragmentos de texto) para identificar mejor los comentarios que expresan puntos de vista extremos. Estos comentarios no se eliminarían, sino que se ocultarían de forma predeterminada con la opción de revelarlos, pero limitando la cantidad de personas que los podrían ver.
Y había debates sobre qué papel podría tener SAIL dentro de Facebook y cómo debería evolucionar con el tiempo. La idea era que el equipo primero generaría pautas para IA responsable para sugerir a los equipos de producto qué deberían hacer y qué no. Pero la esperanza era que, en última instancia, sirviera como el eje central de la empresa para evaluar los proyectos de IA y parar aquellos que no siguieran esas pautas.
Sin embargo, los antiguos empleados describieron lo difícil que podría ser conseguir la aceptación o el apoyo económico cuando el trabajo no mejoraba directamente el crecimiento de Facebook. Por su naturaleza, el equipo no pensaba en el crecimiento y, en algunos casos, proponía ideas contrarias al crecimiento. Como resultado, recibió pocos recursos y languideció. Muchas de sus ideas se mantuvieron como algo teórico.
El 29 de agosto de 2018, eso cambió de repente. En el período previo a las elecciones a mitad del mandato en Estados Unidos, el presidente Donald Trump y otros líderes republicanos intensificaron las acusaciones de que Facebook, Twitter y Google tenían un sesgo anticonservador. Aseguraban que los moderadores de Facebook en particular reprimían las voces conservadoras más que las liberales al aplicar los estándares de la comunidad. Esta acusación luego se desmintió, pero el hashtag #StopTheBias, impulsado por un tuit de Trump, se difundía rápidamente en las redes sociales.
Para Trump, fue el último esfuerzo por sembrar desconfianza en los principales canales de distribución de información del país. Para Zuckerberg, eso amenazó con apartar a los usuarios conservadores de Facebook en Estados Unidos y con la posibilidad de volverlo más vulnerable a la regulación del Gobierno estadounidense liderado por los republicanos. En otras palabras, eso iba en contra del crecimiento de la empresa.
Facebook no me concedió una entrevista con Zuckerberg, pero algunos reportajes anteriores han demostrado cómo Zuckerberg iba complaciendo cada vez más a Trump y a los líderes republicanos. Después de la victoria de Trump en las elecciones, el vicepresidente de Política Pública Global de Facebook y su republicano de más alto nivel, Joel Kaplan, aconsejó a Zuckerberg que debería tener cuidado en el nuevo entorno político.
El 20 de septiembre de 2018, tres semanas después del tuit #StopTheBias de Trump, Zuckerberg se reunió con Quiñonero por primera vez desde la creación de SAIL. Quería saber todo lo que Quiñonero había aprendido sobre el sesgo de la IA y cómo eliminarlo en los modelos de moderación de contenido de Facebook. Al final de la reunión, una cosa quedó clara: el sesgo de la IA se convirtió en la principal prioridad de Quiñonero. "La dirección ha insistido muchísimo en asegurarse de que escalemos en esto de manera agresiva", recuerda el director de ingeniería de Responsible AI, Rachad Alao, que se unió al grupo en abril de 2019.
Fue una victoria para todos. Zuckerberg encontró una manera de evitar las acusaciones del sesgo anticonservador. Y Quiñonero recibió más dinero y equipo para mejorar la experiencia general para los usuarios de Facebook. Podían basarse en la herramienta ya existente de Kloumann para medir y corregir el supuesto sesgo anticonservador en los modelos de moderación de contenido, así como para corregir otros tipos de sesgo en la gran mayoría de los modelos de la plataforma.
Así se creó la posibilidad de evitar que la plataforma discriminara involuntariamente a ciertos usuarios. En esos momentos, Facebook ya tenía miles de modelos ejecutándose al mismo tiempo, y casi ninguno había sido analizado por sesgo. Unos meses más tarde eso generó problemas jurídicos con el Departamento de Vivienda y Desarrollo Urbano (HUD) de EE. UU., que alegó que los algoritmos de la empresa deducían algunos atributos "protegidos" como la raza a partir de los datos de los usuarios y les mostraban anuncios de viviendas en función de dichos atributos, que era una forma ilegal de discriminación. (La demanda aún está pendiente). Schroepfer también predijo que el Congreso de EE. UU. pronto aprobaría leyes para regular la discriminación algorítmica, por lo que Facebook tenía que avanzar en esos esfuerzos de todos modos.
(Facebook niega la idea de que prosiguió su trabajo sobre el sesgo de la IA para proteger su crecimiento o para anticiparse a la regulación. Un portavoz de la empresa afirma: "Creamos el equipo de Responsible AI porque era lo correcto").
Pero reducir el enfoque de SAIL a la equidad algorítmica dejaría de lado todos los demás problemas algorítmicos de Facebook. Sus modelos de recomendación de contenido continuarían impulsando publicaciones, noticias y grupos a los usuarios en su esfuerzo por maximizar la participación, favoreciendo el contenido extremista y contribuyendo al discurso político cada vez más polarizado.
Zuckerberg incluso lo reconoció. Dos meses después de la reunión con Quiñonero, en una nota pública que describe los planes de Facebook para la moderación de contenido, el CEO ilustró los efectos dañinos de la estrategia de participación de la empresa con un gráfico simplificado que mostraba que cuanta más probabilidad había que una publicación violara los estándares de la comunidad de Facebook, más participación recibiría de los usuarios, porque los algoritmos que maximizaban la participación favorecían el contenido incendiario.
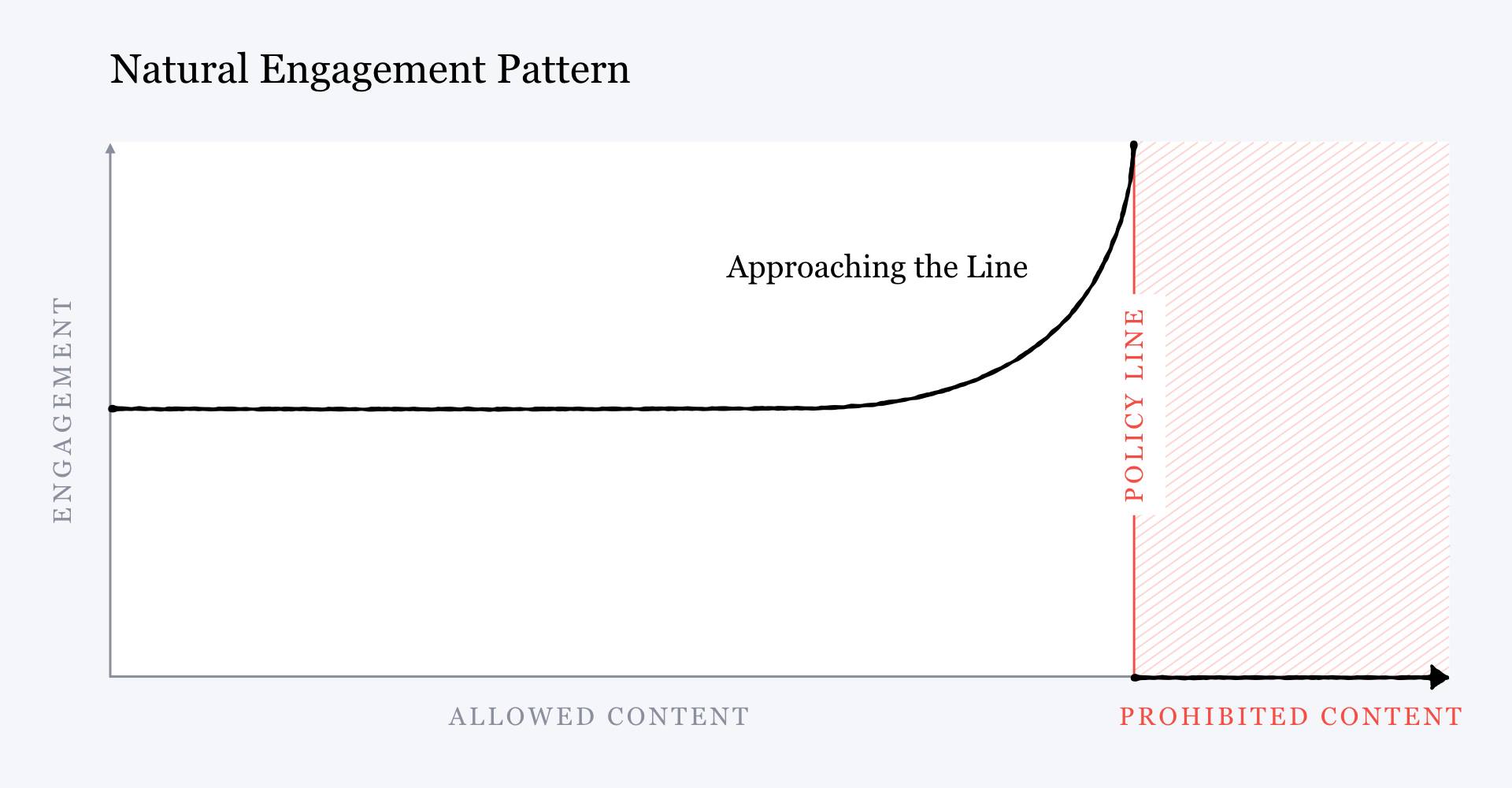
Pero luego Zuckerberg mostró otro gráfico con la relación inversa y escribió que en vez de favorecer el contenido que se acercaba a la violación de los estándares de la comunidad, Facebook podría optar por empezar a "penalizarlo", que supondría "menos distribución y participación" y no más. ¿Cómo se haría esto? Con más IA. Facebook desarrollaría mejores modelos de moderación de contenido para detectar este "contenido límite", para poder empujarlo retroactivamente más abajo en la sección de noticias para reducir su viralidad, explicó.
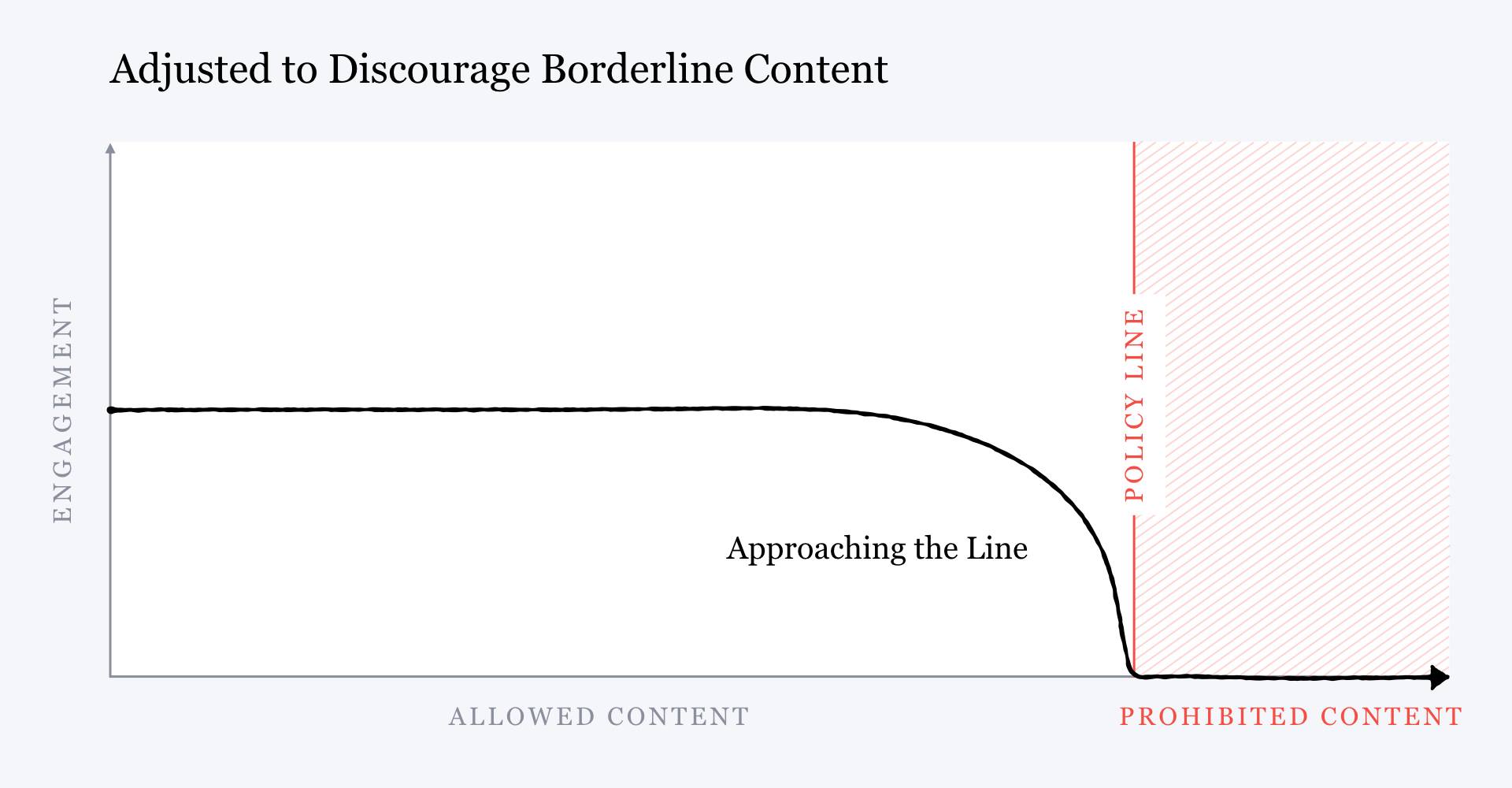
El problema consiste en que, a pesar de todas las promesas de Zuckerberg, esta estrategia, a lo sumo, resulta frágil.
La desinformación y el discurso de odio evolucionan constantemente. Siempre surgen nuevas falsedades y otras personas y grupos se convierten en objetivos. Para detectar las cosas antes de que se vuelvan virales, los modelos de moderación de contenido deben poder identificar con alta precisión ese contenido nuevo no deseado. Pero los modelos de aprendizaje automático no funcionan así.
Un algoritmo que ha aprendido a reconocer la negación del Holocausto no puede detectar de inmediato, por ejemplo, la negación del genocidio rohingya. Se tiene que entrenar en miles, a menudo hasta en millones de ejemplos de un nuevo tipo de contenido antes de aprender a filtrarlo. Incluso entonces, los usuarios pueden aprender a engañar el modelo cambiando las palabras de su publicación o sustituyendo algunas frases incendiarias con eufemismos, haciendo que su mensaje sea ilegible para la IA y, al mismo tiempo, obvio para un usuario humano. Por esa razón, las nuevas teorías de la conspiración pueden salirse rápidamente fuera de control y, en parte, persistir en la plataforma.
Schroepfer, en su entrevista con The New York Times, mencionó estas limitaciones de la estrategia de moderación de contenido de la empresa. El Times publicó: "Cada vez que el Sr. Schroepfer y sus más de 150 especialistas en ingeniería crean soluciones de IA que identifican y sofocan algún contenido nocivo, aparecen publicaciones nuevas y dudosas que los sistemas de IA nunca antes habían visto y, por lo tanto, no se detectan". "Nunca llegará a cero", admitió Schroepfer al periódico.
Mientras tanto, los algoritmos que recomiendan este contenido aún están diseñados para maximizar la participación. Esto significa que todas las publicaciones tóxicas que se escapen de los filtros de moderación de contenido seguirán subiendo más en la sección de noticias apoyadas para llegar a un público mayor. De hecho, un estudio de la Universidad de Nueva York (EE. UU.) descubrió recientemente que entre las páginas de Facebook de los usuarios partidistas, los que publicaban regularmente alguna desinformación política recibieron mayor participación en el período previo a las elecciones presidenciales estadounidenses de 2020 y a los disturbios del Capitolio. Un antiguo empleado que trabajó en temas de integridad de 2018 a 2019 confiesa: "Eso me derrumbó. Lo reconocemos completamente, pero seguimos aumentando la participación".
Pero el equipo SAIL de Quiñonero no trabajaba en este problema. Debido a las preocupaciones de Kaplan y Zuckerberg sobre los conservadores, SAIL se mantuvo centrado en el sesgo. E incluso después de fusionarse con el equipo más grande de Responsible AI, nunca se le ordenó trabajar en los sistemas de recomendación de contenido que pudieran limitar la propagación de la desinformación. Tampoco lo ha hecho ningún otro equipo, como comprobé cuando Entin y otro portavoz me mandaron una lista de todas las iniciativas de Facebook sobre temas de integridad, el término general de la empresa para los problemas que incluyen la desinformación, el discurso de odio y la polarización.
Una portavoz de Facebook explicó: "Ese trabajo no lo realiza un equipo específico porque la empresa no opera así". En cambio, se distribuye entre los equipos que tienen los conocimientos específicos para abordar cómo la clasificación del contenido influye en la desinformación en su parte de la plataforma, resaltó. Pero Schroepfer me había dicho justo lo contrario. Le pregunté por qué el equipo de Responsible AI estaba tan centralizado en vez de dirigir a los equipos existentes para avanzar en este tema. Schroepfer afirmó que era la "mejor práctica" en la empresa.
Y añade: "[Si] es un área importante, tenemos que avanzar rápido, no está bien definido, [creamos] un equipo específico con el liderazgo adecuado. A medida que un campo crece y madura, los equipos de productos asumirán más trabajo, pero el equipo central aún será necesario porque hay que mantenerse al día con el trabajo de vanguardia".
Cuando describí el trabajo del equipo de Responsible AI a otros expertos en ética de la IA y derechos humanos, notaron la incongruencia entre los problemas que abordaba y aquellos, como la desinformación, por los que Facebook es más famoso. "Esto parece haber sido eliminado como producto de Facebook de una manera extraña: de las cosas que Facebook construye y de las cuestiones sobre el impacto en el mundo con las que se enfrenta Facebook", resaltó la científica Rumman Chowdhury, cuya start-up, Parity, asesora a las empresas sobre el uso responsable de la IA y fue adquirida por Twitter después de nuestra entrevista. Le había mostrado a Chowdhury la documentación del trabajo del equipo de Quiñonero. Ella me dijo: "Me sorprende que hablemos de la inclusión, justicia, equidad y no de los problemas reales que ocurren hoy en día".
La directora editorial de la organización sin ánimo de lucro que estudia el impacto de las empresas tecnológicas en los derechos humanos Ranking Digital Rights, Ellery Roberts Biddle, afirma: "Parece que el marco de la 'IA responsable' es completamente subjetivo a lo que la empresa decide que quiere abordar. Es como: 'Inventaremos los términos y luego los cumpliremos'. Ni siquiera entiendo qué quieren decir cuando hablan de lo que es justo. ¿Creen que es justo recomendar que la gente se una a grupos extremistas, como los que irrumpieron en el Capitolio? Si todos reciben la recomendación, ¿eso significa que fue justa? Estamos en un lugar donde hay un genocidio [Myanmar] sobre el cual la ONU, con muchas pruebas, ha podido señalar específicamente a Facebook y a la forma en la que la plataforma promueve el contenido. ¿Cuánto más lejos pueden llegar?"
Durante los últimos dos años, el equipo de Quiñonero ha estado desarrollando la herramienta original de Kloumann, denominada Fairness Flow, que permite a los ingenieros medir la precisión de los modelos de aprendizaje automático para diferentes grupos de usuarios. Pueden comparar la precisión de un modelo de reconocimiento facial en diferentes edades, géneros y tonos de la piel, o la precisión de un algoritmo de reconocimiento de voz en diferentes idiomas, dialectos y acentos.
Fairness Flow también viene con un conjunto de pautas para ayudar a los ingenieros a comprender lo que significa entrenar un modelo "justo". Uno de los problemas más espinosos para hacer que los algoritmos sean justos es que existen diferentes definiciones de imparcialidad, que pueden ser mutuamente incompatibles. Fairness Flow enumera cuatro definiciones que los ingenieros pueden usar según la que mejor se adapte a su propósito, como por ejemplo si un modelo de reconocimiento de voz reconoce todos los acentos con la misma precisión o con un umbral mínimo de precisión.
Pero comprobar la imparcialidad de los algoritmos sigue siendo algo principalmente opcional en Facebook. Ninguno de los equipos que trabajan directamente en la sección de noticias, en el servicio de anuncios u otros productos de Facebook está obligado a hacerlo. Los incentivos salariales todavía siguen vinculados a las métricas de la participación y el crecimiento. Y a pesar de que existen pautas sobre qué definición de imparcialidad usar en una situación determinada, no se aplican.
Este último problema salió a la luz cuando la empresa tuvo que lidiar con las acusaciones de sesgo anticonservador. En 2014, Kaplan fue ascendido de Director de Políticas de EE. UU. a vicepresidente Global de Políticas, y empezó a desempeñar un papel más serio en la moderación del contenido y en las decisiones sobre cómo clasificar las publicaciones en la sección de noticias de los usuarios. Después de que los republicanos iniciaran sus afirmaciones de sesgo anticonservador en 2016, su equipo comenzó a revisar manualmente el impacto de los modelos de detección de desinformación en los usuarios para asegurarse, entre otras cosas, de que no perjudicaran de manera desproporcionada a los conservadores.
Todos los usuarios de Facebook tienen unos 200 "atributos" adjuntos a su perfil que incluyen varias dimensiones enviadas por los usuarios o estimadas por los modelos de aprendizaje automático, como la raza, las preferencias políticas y religiosas, la clase socioeconómica y el nivel de educación. El equipo de Kaplan empezó a usarlos para ensamblar segmentos de usuarios personalizados que reflejaban los intereses mayoritariamente conservadores: los usuarios que, por ejemplo, interactuaban con el contenido, grupos y páginas conservadores. Luego, realizaban análisis especiales para ver cómo las decisiones de moderación de contenido afectarían las publicaciones de esos segmentos, según un antiguo investigador cuyo trabajo estaba sujeto a esas revisiones.
La documentación de Fairness Flow, que el equipo de Responsible AI escribió más tarde, incluye un estudio de caso sobre cómo usar la herramienta en este tipo de situaciones. El equipo escribió que a la hora de decidir si un modelo de desinformación era justo con respecto a la ideología política, "lo justo" no significaba que el modelo tratara por igual a los usuarios conservadores y los liberales. Si los conservadores publican una mayor proporción de desinformación, según el consenso público, entonces el modelo debería alertar sobre una mayor fracción del contenido conservador. Si los liberales publican más desinformación, también debería alertar sobre su contenido con más frecuencia.
Pero los miembros del equipo de Kaplan siguieron exactamente el enfoque opuesto: "lo justo" se entendía en el sentido de que estos modelos no deberían afectar más a los conservadores que a los liberales. Cuando un modelo lo hacía, detenían su implementación y exigían un cambio. Una vez, según me admitió un antiguo investigador, bloquearon un detector de desinformación médica que había reducido notablemente el alcance de las campañas antivacunas. Dijeron a los investigadores que el modelo no se podía implementar hasta que el equipo arreglara esta discrepancia. Pero eso en realidad provocó que el modelo careciera de sentido. "Entonces no tiene sentido", subraya el investigador. Un modelo modificado de esa manera "literalmente no tendría ningún impacto en el problema real" de la desinformación.
"Ni siquiera entiendo lo que quieren decir cuando hablan de lo que es justo. ¿Creen que es justo recomendar que la gente se una a grupos extremistas, como los que irrumpieron en el Capitolio? Si todos reciben la recomendación, ¿eso significa que fue justa?", Ellery Roberts Biddle, la directora editorial de Ranking Digital Rights.
Esto ha ocurrido en innumerables ocasiones, y no solo en moderación del contenido. En 2020, The Washington Post informó de que el equipo de Kaplan había socavado los esfuerzos para mitigar la interferencia electoral y la polarización dentro de Facebook, explicando que podrían contribuir al sesgo anticonservador. En 2018, utilizó el mismo argumento para archivar un proyecto de modificación de los modelos de recomendación de Facebook, a pesar de que los investigadores creían que reduciría la polarización en la plataforma, según Wall Street Journal. Las afirmaciones sobre el sesgo político también debilitaron la propuesta para editar los modelos de clasificación de la sección de noticias que los científicos de datos de Facebook creían que fortalecería la plataforma contra las tácticas de manipulación que Rusia había utilizado en las elecciones estadounidenses de 2016.
Y según The New York Times, antes de las elecciones en 2020, los directivos de Políticas de Facebook utilizaron esta excusa para vetar o debilitar varias propuestas que habrían reducido la difusión de contenido dañino y de odio.
Facebook negó la información del Wall Street Journal en una publicación de blog de seguimiento y mostró su desacuerdo con la descripción del The New York Times en una entrevista con el periódico. Un portavoz del equipo de Kaplan también me explicó que esto no era un patrón de comportamiento y que los casos descritos por el Post, el Journal y el Times eran "casos individuales que creemos que se interpretaron erróneamente". No quiso comentar sobre el reentrenamiento de los modelos de desinformación.
Muchos de estos incidentes ocurrieron antes de que se adoptara Fairness Flow. Pero muestran cómo la búsqueda por parte de Facebook de lo que es justo al servicio del crecimiento ya había tenido un coste elevado para avanzar en los otros desafíos de la plataforma. Y si los ingenieros usaran la definición de justicia que había adoptado el equipo de Kaplan, Fairness Flow podría simplemente sistematizar el comportamiento que favorece la desinformación en vez de ayudar a combatirla.
Un antiguo investigador cree que, a menudo "todo el tema de lo justo" entraba en juego sólo como una forma conveniente de mantener el status quo: "Parece contradecir las cosas que Mark decía públicamente sobre ser justo y equitativo".
La última vez que hablé con Quiñonero fue un mes después de los disturbios en el Capitolio de Estados Unidos. Quería saber cómo esa toma del Congreso estadounidense había afectado su pensamiento y la dirección de su trabajo.
La videollamada fue como siempre: en una ventana se veía a Quiñonero hablando desde su oficina en su casa y en otra estaba Entin, su consejero de relaciones públicas. Le pregunté qué papel creía que había tenido Facebook en los disturbios y si eso había cambiado la función que él creía que tenía Responsible AI. Después de una larga pausa, Quiñonero esquivó la pregunta y empezó a describir el trabajo que había realizado recientemente para promover una mayor diversidad e inclusión entre los equipos de IA.
Volví a hacerle la misma pregunta. Su cámara de Facebook Portal, que utiliza los algoritmos de visión artificial para localizar al hablante, empezó a acercar lentamente su rostro mientras él se mantenía en silencio. Respondió: "No sé si tengo una respuesta fácil a esa pregunta, Karen. Es una pregunta demasiado difícil para mí".
Entin, que se movía rápidamente con una estoica cara de póker, agarró una pelota roja antiestrés.
Le pregunté a Quiñonero por qué su equipo no había buscado antes formas de modificar los modelos de clasificación de contenido de Facebook para reducir la desinformación y el extremismo. Me respondió que eso era responsabilidad de otros equipos (aunque, como verifiqué, ninguno tenía órdenes de trabajar en esa tarea). "No es factible que el equipo de Responsible AI estudie todas esas cosas por sí solo", aclaró. Cuando le pregunté si consideraría que su equipo abordara esos problemas en el futuro, admitió vagamente: "Estoy de acuerdo con usted en que ese será el ámbito de este tipo de conversaciones".
Cerca del final de nuestra entrevista de una hora, Quiñonero comenzó a resaltar que a la IA a menudo se presentaba injustamente como "la culpable". Independientemente de si Facebook usaba la IA o no, la gente seguiría arrojando mentiras y discursos de odio, y ese contenido aún se difundiría por la plataforma, concluyó Quiñonero.
Lo presioné una vez más. Le dije que no podía creer de verdad que los algoritmos no habían hecho absolutamente nada para cambiar la naturaleza de estos problemas. Con un tartamudeo vacilante Quiñonero respondió: "No lo sé". Luego lo repitió, un poco más convencido: "Es mi respuesta más sincera. De verdad. No lo sé".
Cadenas de bloques y aplicaciones
Qué significa estar constantemente contectados unos a otros y disponer de inmensas cantidades de información al instante.
-
Ciberguerra, 'ransomware' y robo de criptodivisas: la claves en ciberseguridad para 2023
"Cuando se trata de eliminar el 'ransomware' desde la fuente, creo que dimos un paso atrás", asegura un experto

-
Descentralización contra regulación: el debate de las criptomonedas en 2023
Este año habrá una lucha por el alma de las finanzas descentralizadas

-
Ethereum abandona la criptominería y adopta la prueba de participación
Nadie sabe exactamente qué le depara a la industria de las criptomonedas tras esta esperada actualización
