Una palabra que está en segundo lugar en la clasificación aparece la mitad de veces que la palabra más común. La palabra que ocupa el tercer puesto aparece un tercio menos, y así sucesivamente.
nEn inglés, la palabra más popular es the (artículo definido que equivale a el, la, los y las en español), que representa aproximadamente el 7 % de todas las palabras, seguida por and (conjunción que equivale a y en español en su forma simple), que se utiliza el 3,5 % de las ocasiones. De hecho, la mitad de todas las apariciones de palabras se refieren a solo 135 términos. Así que algunas palabras se utilizan muy a menudo, mientras que otras casi nunca se usan.
n
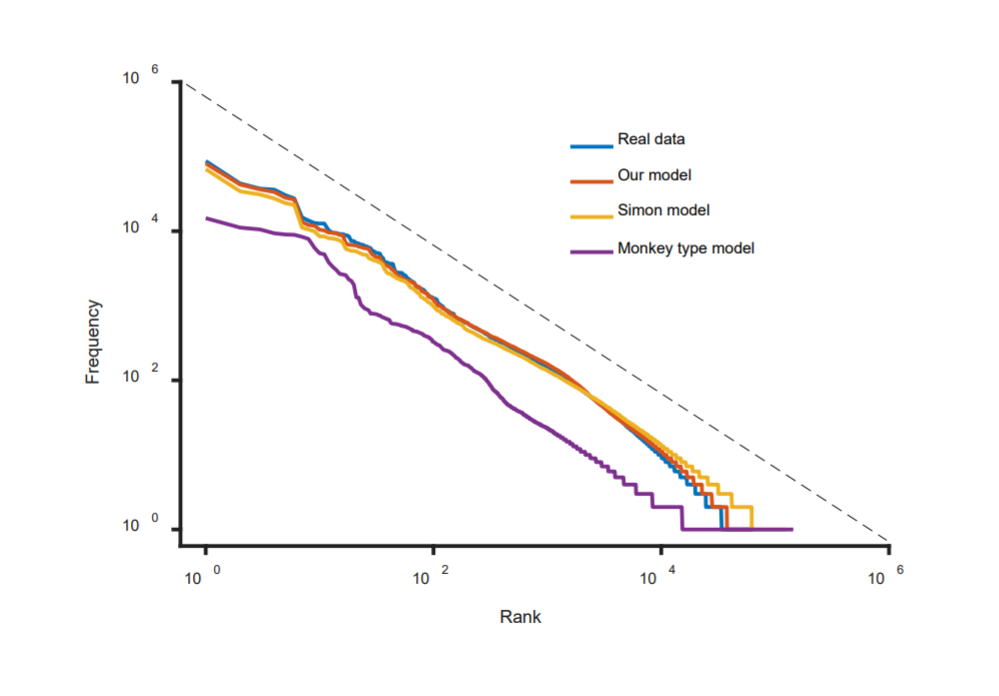
Gráfico: Eje vertical: Frecuencia. Eje horizontal: clasificación. Azul: Datos reales. Rojo: Nuestro modelo. Amarillo: Modelo de Simon. Violeta: Modelo de mono con máquina de escribir.
nPero, ¿por qué pasa esto? Una posibilidad intrigante es que el cerebro procese las palabras más comunes de forma diferente a las demás, un enfoque según el cual, el estudio de la distribución de Zipf estaría revelando información importante sobre este proceso cerebral.
nPero este enfoque tiene un problema. Los lingüistas no están de acuerdo en que la distribución estadística de la frecuencia de las palabras sea consecuencia de un proceso cognitivo. En lugar de eso, algunos afirman que esta distribución es el resultado de errores estadísticos asociados con palabras de baja frecuencia, que pueden producir distribuciones similares.
nPara zanjar el debate haría falta un estudio más amplio en una amplia gama de idiomas. Tal estudio a gran escala sería más poderoso estadísticamente y capaz de separar estas posibilidades. Y eso es justo lo que ofrece una investigación de un equipo de investigadores de la Universidad de Comunicación de China en Pekín (China) liderados por Shuiyuan Yu. Los científicos han detectado que la ley de Zipf se cumple en 50 idiomas distintas familias lingüísticas, como la indoeuropea, la urálica, la altaica, la caucásica, la sino-tibetana, la drávida, la afroasiática, etcétera.
nPara el equipo, el hecho de que los distintos idiomas presenten una estructura común es síntoma de que la propia estructura no puede deberse a errores estadísticos. En su opinión, este fenómeno sugiere que el cerebro procesa las palabras comunes de forma diferente a las poco comunes, una idea que tiene consecuencias importantes para el procesamiento del lenguaje natural y la generación automática de texto.
nEl método de Yu y su equipo es sencillo. Como base, utilizaron dos grandes corpus de texto, el British National Corpus y el Leipzig Corpus; incluyen muestras de 50 idiomas diferentes y cada muestra contiene, como mínimo, 30.000 oraciones y hasta 43 millones de palabras.
nLos investigadores encontraron que las frecuencias de las palabras en todos los idiomas siguen una modificación de la ley de Zipf en la cual la distribución se puede dividir en tres segmentos. "Los resultados estadísticos muestran que las leyes de Zipf en 50 idiomas comparten un patrón estructural de tres segmentos, en el que cada segmento muestra propiedades lingüísticas distintivas", explica Yu.
nEl equipo ha intentado simular el patrón con varios modelos de creación de palabras. Uno es el modelo de un mono en una máquina de escribir (el teorema del mono infinito), que genera letras al azar que forman palabras cada vez que se pulsa un espacio.
nEste proceso genera una distribución de ley potencial como la ley de Zipf. Sin embargo, no puede replicar la estructura de tres segmentos que Yu y su equipo han encontrado. Esta estructura tampoco puede generarse por errores asociados con palabras de baja frecuencia.
nSin embargo, los investigadores sí fueron capaces de reproducirla mediante un modelo que simula el funcionamiento del cerebro: la teoría del proceso dual, que señala que el cerebro tiene dos formas de funcionar diferentes.
nLa primera es el pensamiento rápido e intuitivo que requiere poco o ningún razonamiento. Se cree que este tipo de pensamiento ha evolucionado para permitir que los humanos reaccionen rápidamente en situaciones de amenaza. Por lo general, proporciona buenas soluciones a problemas difíciles, como el reconocimiento de patrones, pero las situaciones no intuitivas permiten engañarlo fácilmente.
nPero los humanos son capaces de pensar de una forma mucho más racional. Este segundo tipo de pensamiento es más lento, más calculado y deliberado. Este es el tipo de pensamiento que nos permite resolver problemas complejos como los acertijos matemáticos.
nLa teoría del doble proceso sugiere que las palabras comunes en inglés como the y and se procesan mediante el pensamiento rápido e intuitivo y, por lo tanto, se utilizan con más frecuencia. Estas palabras forman una especie de columna vertebral para las oraciones.
nSin embargo, las palabras y frases menos comunes como hipótesis y lenguaje requieren un pensamiento mucho más cuidadoso. Y debido a esto, ocurren con menos frecuencia.
nDe hecho, cuando Yu y su equipo simularon el proceso dual, se dieron cuenta de que produce a la misma estructura de tres segmentos en la distribución de frecuencia de palabra que midieron en 50 idiomas diferentes.
nEl primer segmento refleja la distribución de palabras comunes, el último segmento refleja la distribución de palabras poco frecuentes y el segmento intermedio es el resultado del cruce de estos dos segmentos. "Estos resultados muestran que la ley de Zipf en los idiomas está motivada por mecanismos cognitivos como el procesamiento dual que rigen los comportamientos verbales humanos", explican Yu y su equipo.
nEs un trabajo interesante. La idea de que el cerebro humano procesa la información de dos formas diferentes ha ganado un impulso considerable en los últimos años, sobre todo por el libro Thinking, Fast and Slow del psicólogo ganador del premio Nobel Daniel Kahneman, que ha estudiado esta idea en detalle.
nUn acertijo famoso que se utiliza para desencadenar el pensamiento rápido y lento es este:
n"Un bate y una pelota cuestan un euro con 10 céntimos en total. El bate cuesta un euro más que la pelota. ¿Cuánto cuesta la pelota?".
nLa respuesta, por supuesto, es cinco céntimos. Pero, de forma instintiva, casi todo el mundo se siente inclinado a responder 10 céntimos. Eso es porque 10 céntimos parece la respuesta correcta. Es el orden correcto de magnitud y es lo que sugiere el enfoque del problema. Esa respuesta proviene del lado rápido e intuitivo de su cerebro.
nPero está mal. Para hallar la respuesta correcta se necesita a la parte más lenta y calculadora de su cerebro.
nYu y su equipo afirman que estos dos mismos procesos están involucrados en la generación de oraciones. La parte de pensamiento rápido de su cerebro crea la estructura básica de la oración (las palabras marcadas en negrita aquí). Las otras palabras requieren la parte más lenta y calculadora de su cerebro.
nEs este proceso dual el que conduce a la ley de Zipf dividida en tres segmentos.
nEso debería tener consecuencias interesantes para los informáticos que trabajan en el procesamiento del lenguaje natural. Este campo se ha beneficiado de grandes avances en los últimos años. Estos provienen de algoritmos de aprendizaje automático, pero también de grandes bases de datos de texto recopiladas por compañías como Google.
nPero generar lenguaje natural sigue siendo difícil. No hace falta conversar mucho tiempo con Siri, Cortana o el asistente de Google para encontrar sus límites en el arte de la conversación. Así que una mejor comprensión de cómo los humanos generan oraciones podría ayudar mucho. Zipf seguramente habría estado fascinado.
nRef: arxiv.org/abs/1807.01855 : Zipf’s Law in 50 Languages: Its Structural Patte , Linguistic Interpretation, and Cognitive Motivation
n