Los cortes de definición normal comprimidos con los programas actuales son un 60 % más pesados que los que logra la nueva técnica. Aunque todavía no puede usarse en tiempo real para vídeo en directo, ayudará a que internet no se sature a medida que el formato sigue popularizándose
En internet hay vídeos por todas partes. Alrededor del 75 % del tráfico es contenido en vídeo, y se espera que este volumen se multiplique por tres para el año 2021. Si no queremos que la insaciable demanda de vídeos de gatitos y servicios de transmisión en directo (streaming) "atasquen las tuberías" para siempre, entonces, tendremos que popularizar los vídeos comprimidos. La compresión es el proceso de recodificación de un archivo de vídeo para que pese menos que el original. Pero las técnicas de compresión actuales están un tanto anticuadas para los estándares de la tecnología moderna. "La base de los existentes algoritmos de compresión de vídeo no han cambiado mucho en los últimos 20 años", el investigador de WaveOne Oren Rippel, cuya compañía está utilizando aprendizaje profundo para adaptar la compresión de vídeo al siglo XXI.
El equipo ha usado este enfoque de inteligencia artificial (IA) para desarrollar un nuevo algoritmo de compresión que supera significativamente a los códecs de vídeo actuales. La investigación detalla: "Según nuestro conocimiento, este es el primer método basado en aprendizaje automático con este objetivo".
La idea básica de la compresión de vídeo consiste en eliminar los datos redundantes de un código y reemplazarlos con una descripción más corta que siga permitiendo reproducir el vídeo. Casi todas las técnicas actuales se realizan en dos pasos.
El primero se centra en comprimir el movimiento: busca objetos en movimiento e intenta predecir dónde estarán en el siguiente fotograma. Luego, en lugar de registrar los píxeles asociados con este objeto en movimiento en cada fotograma, el algoritmo codifica solo la forma del objeto, junto con la dirección del movimiento. De hecho, algunos algoritmos observan los siguientes fotogramas para determinar el movimiento con mayor precisión, aunque esto obviamente no funciona en transmisiones en vivo. El resultado es que el vídeo comprimido simplemente "traslada" el objeto a través de la pantalla.
El segundo paso de la compresión elimina otras redundancias entre un fotograma y el siguiente. Entonces, en lugar de registrar el color de cada píxel en un cielo azul, un algoritmo de compresión identifica toda la región coloreada del mismo color y especifica que debe mantenerse igual en los siguientes fotogramas. Así que estos píxeles permanecen del mismo color hasta que se les indique el cambio. Esto se llama compresión residual.
El nuevo y pionero método de Rippel utiliza el aprendizaje automático para mejorar ambos pasos. En la compresión de movimiento, el sistema ha encontrado nuevas redundancias de movimiento que los códecs convencionales nunca habían podido explotar. Por ejemplo, la cabeza de una persona que pasa de una vista frontal a una vista lateral siempre produce un resultado similar. "Los códecs tradicionales no pueden predecir una cara de perfil desde una vista frontal", explican Rippel y sus compañeros. En cambio, el nuevo códec aprende este tipo de patrones de espacio y tiempo y los usa para predecir los siguientes fotogramas.
Otro problema consiste en distribuir el ancho de banda disponible entre el movimiento y la compresión residual. En algunas escenas, la compresión de movimiento es más importante; en otras, la compresión residual ofrece la mejor opción. El intercambio óptimo de las dos difiere de un fotograma a otro.
Para los algoritmos de compresión tradicionales esto resulta difícil porque comprimen ambos procesos por separado. Eso significa que no hay una manera fácil de intercambiarlos. Rippel y sus colegas han comprimido ambas señales al mismo tiempo y han utilizado la complejidad del fotograma para decidir cómo distribuir el ancho de banda entre ellos de la manera más eficiente.
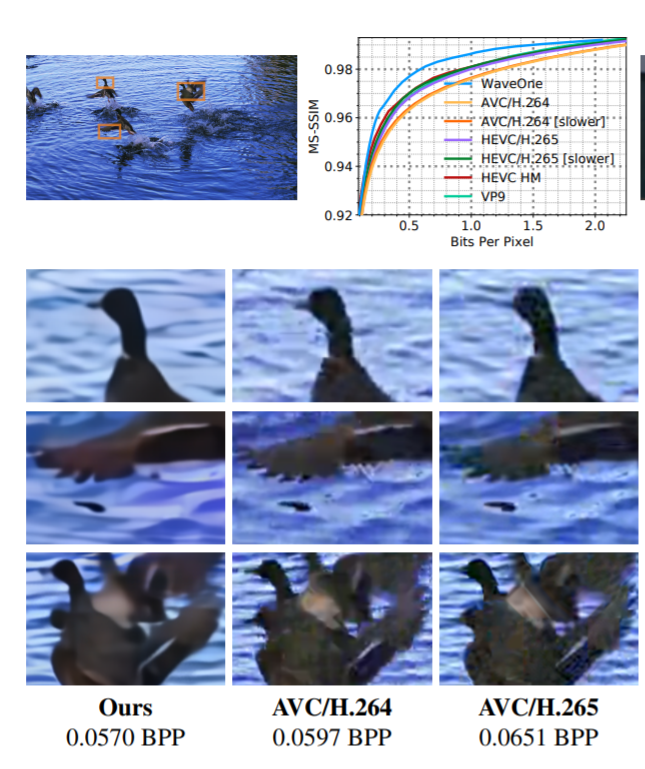
Estas y otras mejoras han permitido a los investigadores crear un algoritmo de compresión que supera significativamente a los códecs tradicionales. Al comprimir un vídeo de alta definición (1080 píxeles), los algoritmos de compresión ordinarios, como H.265 y VP9, producen archivos un 20 % más grandes que los que produce el nuevo algoritmo.
Y los resultados son aún mejores para los vídeos en definición estándar, como HEVC / H.265 y AVC / H.264. Normalmente, estos códecs producen archivos hasta un 60 % más grandes que el nuevo método de este equipo.
Se trata de un avance impresionante que podría reducir significativamente el tamaño y los tiempos de descarga relacionados con un vídeo online. Sin embargo, el nuevo planteamiento tiene algunas deficiencias. Quizás la más importante sea su eficiencia computacional, el tiempo que necesita para codificar y decodificar los vídeos. En una tarjeta gráfica Nvidia Tesla V100 y en vídeos de tamaño VGA, el nuevo decodificador funciona a una velocidad media de alrededor de 10 fotogramas por segundo con el codificador funcionando a alrededor de dos fotogramas por segundo. Esto tiene aplicación limitada para una transmisión en vivo.
Por supuesto, los investigadores esperan realizar importantes mejoras a medida que su trabajo avance. "La velocidad actual no es suficiente para su uso en tiempo real, pero se mejorará sustancialmente en el futuro", afirman. Esto significa que gracias a este método de aprendizaje automático, los futuros cibernavegadores deberían poder descargarse Juegos de Tronos o vídeos de gatos en tiempos récord y transmitir sus partidos de fútbol de alta definición de manera más eficiente que nunca.
Ref: arxiv.org/abs/1811.06981: Learned Video Compression
Inteligencia Artificial
La inteligencia artificial y los robots están transformando nuestra forma de trabajar y nuestro estilo de vida.
-

-
La IA generativa puede convertir tus recuerdos en fotos que nunca existieron
El proyecto Synthetic Memories ayuda a familias de todo el mundo a recuperar un pasado que nunca se fotografió

-
"La pregunta es cuánta participación humana se necesita para que algo sea arte"
Alex Reben hace arte con (y sobre) IA. Hablé con él sobre lo que la nueva ola de modelos generativos significa para el futuro de la creatividad humana