
Gebru, una líder muy respetada en la investigación de ética en la IA, es conocida por ser coautora de un artículo revolucionario que mostró que el reconocimiento facial es menos preciso en la identificación de las mujeres y las personas de color, lo que significa que su uso podría terminar discriminándolas. También cofundó el grupo afín Black in AI (negros en inteligencia artificial) y defiende la diversidad en la industria tecnológica. El equipo que ayudó a reunir en Google es uno de los más diversos en IA e incluye a muchos expertos con méritos propios. Sus compañeros en el campo envidiaban a este grupo por su trabajo crítico que a menudo desafiaba las prácticas convencionales de la IA.
nUna serie de tuits, correos electrónicos filtrados y reportajes en los medios han mostrado que la salida de Gebru fue la culminación de un conflicto sobre otro artículo del que fue coautora. El jefe de IA de Google, Jeff Dean, explicó a sus colegas en un correo electrónico inte o (que después ha publicado online) que el artículo "no había cumplido con nuestro estándar de publicación" y que Gebru había dicho que dimitiría a menos que Google cumpliera con varias condiciones que la empresa no estaba dispuesta a cumplir. Gebru tuiteó que había pedido negociar "un último día" en su cargo al volver de las vacaciones. Pero antes de su regreso ya se le había impedido el acceso a su cuenta de correo electrónico corporativo.
nMuchos otros líderes en el campo de la ética de la inteligencia artificial argumentan virtualmente que la compañía la expulsó debido a algunas verdades incómodas que Gebru estaba descubriendo sobre la línea central de la investigación de Google y que quizá fue la clave. Más de 1.400 miembros del personal de Google y otros 1.900 partidarios también firmaron una carta de protesta.
nMuchos detalles sobre la serie exacta de acontecimientos que provocaron la salida de Gebru de Google no están claros y tanto ella como Google se han negado a comentarlos más allá de sus publicaciones en las redes sociales. Pero MIT Technology Review ha obtenido una copia del mencionado trabajo de investigación de la coautora y profesora de lingüística computacional de la Universidad de Washington (EE. UU.) Emily M. Bender. Aunque Bender nos pidió que no publicáramos el artículo en sí porque los autores no querían que circulara online un primer borrador, el trabajo nos permite hace os una idea de las cuestiones que Gebru y sus colegas estaban planteando en relación con la IA y que podrían estar provocando la preocupación de Google.
nOn the Dangers of Stochastic Parrots: Can Language Models Be Too Big? (Sobre los peligros de los loros estocásticos: ¿podrían los modelos de lenguaje ser demasiado grandes?) expone los riesgos de los grandes modelos de lenguaje: los sistemas de IA entrenados con enormes cantidades de datos de texto se han vuelto más populares, y cada vez mayores, en los últimos tres años. Actualmente, en las condiciones adecuadas, estos modelos resultan extraordinariamente buenos para generar un texto nuevo aparentemente convincente y con sentido, y, a veces, para analizar el significado del lenguaje. No obstante, en la introducción del trabajo, Gebru y sus compañeros se "preguntan si se ha pensado suficiente en los posibles riesgos asociados con el desarrollo de esta IA y en las estrategias para mitigar estos riesgos".
nEl artículo en el centro de la polémica
nEl artículo, que se basa en el trabajo de otros investigadores, expone la historia del procesamiento del lenguaje natural (PLN), una descripción general de los cuatro riesgos principales de los grandes modelos de lenguaje y sugerencias para futuras investigaciones. Dado que el conflicto en Google parece estar relacionado con los riesgos, nos hemos centrado en resumir esa parte del estudio.
nLos costes ambientales y económicos
nEl entrenamiento de grandes modelos de IA consume mucha energía por el procesamiento computacional. Gebru y los coautores se refieren al artículo de 2019 de la investigadora Emma Strubell y sus colaboradores sobre las emisiones de carbono y los costes económicos de los grandes modelos de lenguaje. Su trabajo mostró que el consumo de energía y la huella de carbono se han disparado desde 2017, ya que los modelos van entrenándose cada vez con más datos.
n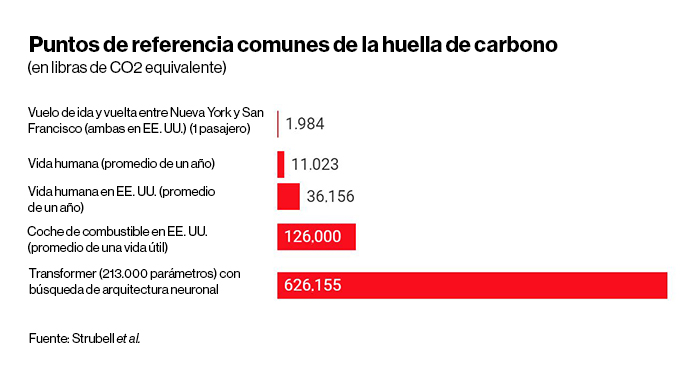
El estudio de Strubell descubrió que entrenar un modelo de lenguaje con un tipo específico de método conocido como búsqueda de arquitectura neuronal (NAS, por sus siglas en inglés) habría producido el equivalente a 626.155 libras (284.000 kilogramos) de dióxido de carbono, aproximadamente el promedio de las emisiones de cinco coches estadounidenses durante toda su vida útil. El entrenamiento de una versión del modelo de lenguaje de Google, BERT, que sustenta el motor de búsqueda de la compañía, produjo 1.400 libras (635 kilogramos) de dióxido de carbono equivalente, según la estimación de Strubell, casi lo mismo que un vuelo de ida y vuelta entre la ciudad de Nueva York y San Francisco (ambas en EE. UU.). Estos números deben apreciarse como mínimos, al igual que el coste de entrenar un modelo una sola vez. En la práctica, los modelos se entrenan y reentrenan muchas veces durante la investigación y el desarrollo.
n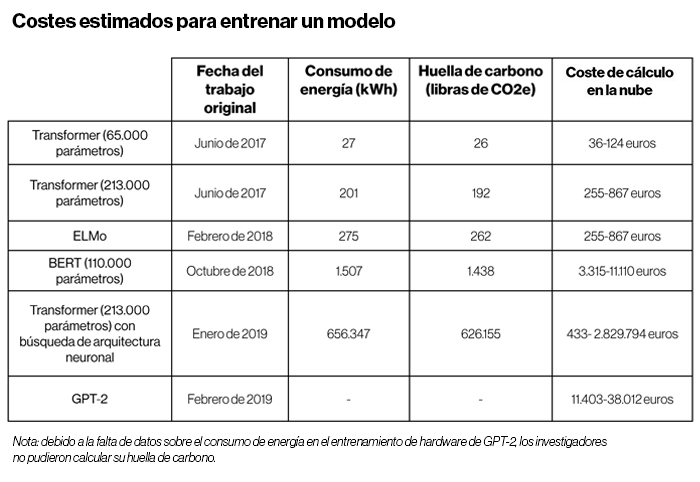
El borrador del trabajo de Gebru señala que los recursos necesarios para construir y mantener los modelos de IA tan grandes significan que se tiende a beneficiar a las organizaciones ricas, mientras que el cambio climático afecta con más fuerza a las comunidades marginadas. "Ya es hora de que los investigadores prioricen la eficiencia energética y el coste para reducir el impacto ambiental negativo y el acceso desigual a los recursos", escriben.
nDatos masivos, modelos inabarcables
nLos grandes modelos de lenguaje también se entrenan con cantidades de texto que aumentan exponencialmente. Esto supone que los investigadores intentan reunir todos los datos posibles de inte et, por lo que existe el riesgo de que aparezca el lenguaje racista, sexista y abusivo en los datos de entrenamiento.
nUn modelo de inteligencia artificial entrenado para considerar el lenguaje racista como algo normal es obviamente malo. Además, los investigadores destacan un par de problemas más delicados. Uno es que la evolución del lenguaje tiene un papel importante en el cambio social: los movimientos MeToo (Yo También) y Black Lives Matter (Las Vidas Negras Importan), por ejemplo, han intentado establecer un nuevo vocabulario antisexista y antirracista. Un modelo de inteligencia artificial entrenado con inmensas áreas de inte et no estará sintonizado con los matices de este vocabulario y no generará ni interpretará el lenguaje de acuerdo con estas nuevas normas culturales.
nTampoco captará el lenguaje y las normas de los países y pueblos que tienen menos acceso a inte et y, por lo tanto, una menor huella lingüística online. El resultado es que el lenguaje generado por IA se homogeneizará, reflejando las prácticas de los países y comunidades más ricos.
nAdemás, debido a que los conjuntos de datos de entrenamiento son enormes, resulta difícil inspeccionarlos para encontrar estos sesgos arraigados. "Una metodología que se basa en conjuntos de datos demasiado grandes para documentarse es, por lo tanto, intrínsecamente arriesgada", concluyen los investigadores. "Si bien la documentación permite asumir una posible responsabilidad [...] los datos de entrenamiento indocumentados perpetúan el daño sin la posibilidad de recurrir".
nEl coste de oportunidad de la investigación
nLos investigadores resumen el tercer desafío como el riesgo de un "esfuerzo de investigación mal dirigido". Aunque la mayoría de los investigadores de IA reconocen que los grandes modelos de lenguaje en realidad no entienden el lenguaje y son simplemente excelentes para manipularlo, las grandes empresas tecnológicas (las llamadas Big Tech) pueden ganar dinero con los modelos que manipulan el lenguaje con mayor precisión y por eso siguen invirtiendo en ellos. "Este esfuerzo de investigación trae consigo el coste de oportunidad", escriben Gebru y sus colegas. No se dedica tanto esfuerzo a trabajar en los modelos de IA que podrían lograr la comprensión o a conseguir buenos resultados con conjuntos de datos más pequeños y cuidadosamente seleccionados (y que, por lo tanto, también consumirían menos energía).
nEl problema de que la IA no entienda lo que dice
nSegún los investigadores, el problema final con los grandes modelos de lenguaje consiste en que, como son tan buenos en imitar el lenguaje humano real, resulta fácil usarlos para engañar a la gente. Ha habido algunos casos populares, como el de un estudiante universitario que publicaba un blog con consejos de productividad y autoayuda en generados por IA y que se volvió viral.
nLos peligros son obvios: los modelos de inteligencia artificial podrían usarse para generar desinformación sobre las elecciones o sobre la pandemia de coronavirus (COVID-19), por ejemplo. También pueden equivocarse inadvertidamente cuando se utilizan para la traducción automática. Los investigadores mencionan un ejemplo: en 2017, Facebook tradujo mal la publicación de un hombre palestino que decía "buenos días" en árabe como "hay que atacarlos" en hebreo, lo que llevó a su arresto.
nPor qué el artículo era controvertido
nEl artículo de Gebru y Bender tiene seis coautores, cuatro de los cuales son investigadores de Google. Bender pidió no revelar sus nombres por miedo a posibles repercusiones. Ella, sin embargo, es catedrática. "Creo que esto resalta el valor de la libertad académica", destaca.
nEl objetivo del artículo, según Bender, era tomar nota del panorama de la investigación actual en el procesamiento del lenguaje natural. "Estamos trabajando a una escala en la que las personas que construyen las cosas no pueden en realidad abordar los datos", explica. "Y como las ventajas son tan obvias, es especialmente importante dar un paso atrás y pregunta os, ¿cuáles son los posibles inconvenientes? ¿Cómo obtener los beneficios de esto mientras mitigamos el riesgo?"
nEn su correo electrónico inte o, Dean, el responsable de IA de Google, añadió que una de las razones por las que el artículo "no cumplió con nuestro estándar" era que "ignoró demasiadas investigaciones relevantes". Específicamente, señaló que no había mencionado los trabajos más recientes sobre cómo hacer que los grandes modelos de lenguaje sean más eficientes energéticamente y mitigar los problemas de sesgos.
nSin embargo, los seis colaboradores contaron con una amplia variedad de estudios. La lista de citas del artículo, con 128 referencias, es considerablemente larga. "Es el tipo de trabajo que ningún autor individual o ni siquiera dos autores podrían realizar", aseguró Bender. "Realmente requirió esta colaboración".
nLa versión del artículo que hemos consultado también hace referencia a varios esfuerzos de investigación para reducir el tamaño y los costes computacionales de los grandes modelos de lenguaje y para medir el sesgo de los modelos. No obstante, el trabajo sostiene que estos esfuerzos no han sido suficientes. "Estoy muy abierta a ver qué otras referencias deberíamos incluir", añade Bender.
nEl investigador de IA de Google en la oficina de Montreal (Canadá) Nicolas Le Roux publicó más tarde en Twitter que el razonamiento del correo electrónico de Dean era inusual. "Mis trabajos siempre se comprobaban por la posible divulgación de material sensible, nunca por la calidad de las consultas bibliográficas", explicó.
nnnNow might be a good time to remind everyone that the easiest way to discriminate is to make stringent rules, then to decide when and for whom to enforce them.
n— Nicolas Le Roux (@le_roux_nicolas) December 3, 2020
nMy submissions were always checked for disclosure of sensitive material, never for the quality of the literature review.
En su correo electrónico, Dean también destaca que Gebru y sus colegas le dieron a Google AI solo un día para la revisión inte a del artículo antes de enviarlo a una conferencia para su publicación. Dean escribió que "nuestro objetivo es competir con las revistas revisadas por pares en términos del rigor y la atención en la forma en la que revisamos los trabajos de investigación antes de su publicación".
nnnI understand the conce over Timnit’s resignation from Google. She’s done a great deal to move the field forward with her research. I wanted to share the email I sent to Google Research and some thoughts on our research process.https://t.co/djUGdYwNMb
n— Jeff Dean () (@JeffDean) December 4, 2020
Bender indicó que la conferencia también sometería el artículo a un proceso de revisión sustancial: "La investigación es siempre una conversación y siempre un trabajo en desarrollo". Otras personas, incluido un exdirector de relaciones públicas de Google, William Fitzgerald, han puesto en duda aún más la afirmación de Dean.
nnnThis is such a lie. It was part of my job on the Google PR team to review these papers. Typically we got so many we didn't review them in time or a researcher would just publish & we wouldn't know until afterwards. We NEVER punished people for not doing proper process. https://t.co/hNE7SOWSLS pic.twitter.com/Ic30sVgwtn
n— William Fitzgerald (@william_fitz) December 4, 2020
Google ha sido pionero en muchas de las investigaciones fundamentales que desde entonces han llevado a la reciente explosión de los grandes modelos de lenguaje. Google AI fue el primero en inventar el modelo de lenguaje Transformer en 2017 que sirve de base para el modelo posterior de la compañía, BERT, y para GPT-2 y GPT-3 de OpenAI. BERT, como se señaló anteriormente, también está detrás del motor de búsqueda de Google, la gran fuente de ingresos de la empresa.
nA Bender le preocupa que las decisiones de Google puedan crear "un efecto desalentador" en la futura investigación sobre la ética de la IA. Muchos de los principales expertos en ese campo trabajan en grandes empresas de tecnología porque ahí es donde está el dinero. "Eso ha sido beneficioso de muchas formas", admite. "Pero acabamos teniendo un ecosistema que podría no tener los mejores incentivos para el progreso de la ciencia para el mundo".
n