Estamos en Toronto porque Geoffrey Hinton está en Toronto, y Geoffrey Hinton es el padre del "aprendizaje profundo" (ver TR10: aprendizaje profundo), la técnica detrás de toda la emoción que hay ahora mismo ento o a la inteligencia artificial. Jacobs afirma: "Dentro de 30 años vamos a mirar hacia atrás y decir que Geoff es el Einstein de la inteligencia artificial; o del aprendizaje profundo, eso a lo que llamamos IA". Entre los investigadores más prominentes del campo del aprendizaje profundo, Hinton tiene más citas que los tres siguientes juntos. Sus estudiantes y posdoctorados ahora están dirigiendo los laboratorios de IA en Apple, Facebook y OpenAI. El propio Hinton es uno de los principales científicos del equipo de de IA de Google Brain. De hecho, casi todos los logros de la última década en inteligencia artificial, traducción, reconocimiento de voz, reconocimiento de imágenes y juegos, se deben en parte al trabajo de Hinton.
nEl Instituto Vector, este monumento a las ideas de Hinton, es un centro de investigación en el que empresas de todo Estados Unidos y Canadá, como Google, Uber y Nvidia, financiarán proyectos para comercializar las tecnologías de inteligencia artificial. El dinero ha llegado más rápido de lo que Jacobs podría haberlo pedido; dos de sus cofundadores encuestaron a las empresas del área de Toronto y la demanda de expertos en inteligencia artificial resultó ser 10 veces la que Canadá produce cada año. El Vector es, en cierto sentido, la zona cero del esfuerzo mundial para girar en to o al aprendizaje profundo: encontrar usos para la técnica, enseñarla, refinarla y aplicarla. Se están construyendo los centros de datos, los rascacielos se están llenando de start-ups, toda una generación de estudiantes se especializa en este campo.
nLa impresión que da el piso de Vector, vacío y con eco, a punto de ser llenado, es que se encuentra al principio de algo. Pero lo curioso del aprendizaje profundo es la edad que tienen sus ideas clave. El principal artículo de Hinton, junto con sus colegas David Rumelhart y Ronald Williams, fue publicado en 1986. El trabajo desarrolló una técnica llamada retropropagación o retroprop para abreviar. La retroprop, en palabras del psicólogo computacional de Princeton (EEUU) Jon Cohen, es "en lo que todo el aprendizaje profundo se basa, literalmente todo".
nCuando se simplifica, la inteligencia artificial actual es básicamente aprendizaje profundo, y el aprendizaje profundo es retroprop. Esto podría sorprender, dado que la retroprop tiene más de 30 años. Vale la pena entender cómo ocurrió eso, cómo una técnica pudo estar en letargo durante tanto tiempo y luego causar tal explosión, porque una vez que entienda la historia de la retroprop, empezará a comprender la fase actual de la inteligencia artificial, y en particular el hecho de que tal vez no estamos al principio de una revolución sino al final.
nJustificación
nEl paseo desde el Instituto Vector hasta la oficina de Hinton en Google, donde pasa la mayor parte de su tiempo (ahora es profesor emérito de la Universidad de Toronto), es una especie de anuncio viviente de la ciudad, al menos durante el verano. Puede entenderse por qué Hinton, originario de Reino Unido, se mudó aquí en la década de 1980 después de trabajar en la Universidad Ca egie Mellon (CMU) en Pittsburgh (EEUU).
nEn la calle, incluso en el centro de la ciudad cerca del distrito financiero, te sientes como si realmente hubieras salido a la naturaleza. Es el olor, creo: limo húmedo en el aire. Toronto fue construido sobre barrancos boscosos y se dice que es "una ciudad dentro de un parque"; a medida que se ha urbanizado, el gobie o local ha establecido estrictas restricciones para mantener el dosel arbóreo. Al aterrizar, las partes exteriores de la ciudad parecen exuberantes, como de caricatura.
nnTal vez no estamos al principio de una revolución sino al final
n
Toronto es la cuarta ciudad más grande de Norteamérica, y la más diversa: más de la mitad de la población nació fuera de Canadá. Eso se nota al caminar por ella. El gentío en el corredor tecnológico parece menos "San Francisco" (jóvenes blancos en sudaderas con capucha) y más inte acional. Hay atención médica gratuita y buenas escuelas públicas, la gente es amistosa, y el orden político se inclina relativamente hacia la izquierda y es estable; y todo esto atrae a gente como Hinton, quien dice que dejó los Estados Unidos por el escándalo Irán-Contra. Es una de las primeras cosas de las que hablamos cuando voy a conocerlo, justo antes del almuerzo.
n"La mayoría de la gente en la CMU pensó que era perfectamente razonable que Estados Unidos invadiera Nicaragua. De alguna manera pensaron que eran los dueños", afirma. Me cuenta que hace poco ha hecho un gran avance en un proyecto: "conseguir un ingeniero junior muy bueno". Se trata de una mujer llamada Sara Sabour, una iraní a la que se le negó una visa para trabajar en Estados Unidos. La oficina de Google en Toronto la reclutó.
nHinton, que tiene 69 años, tiene el rostro amable, flaco, de aspecto de gigante bonachón inglés, con una boca delgada, grandes orejas y una nariz orgullosa. Nació en Wimbledon (Inglaterra), y suena, cuando habla, como el narrador de un libro infantil sobre ciencia: curioso, atractivo, entusiasta por explicar las cosas. Es gracioso y un poco showman. Se mantiene de pie durante todo el tiempo que hablamos, porque, resulta, sentarse es demasiado doloroso. "Me senté en junio de 2005 y fue un error", me dice, dejando que la extraña frase aterrice antes de explicar que un disco de su espalda le da problemas. Eso significa que no puede volar, y antes ese mismo día tuvo que llevar un artefacto que parecía una tabla de surf a la clínica del dentista, para que pudiera acostarse sobre él mientras se le examinaba la raíz de un diente agrietado.
nEn la década de 1980, Hinton era, como ahora, un experto en redes neuronales, un modelo muy simplificado de la red de neuronas y sinapsis del cerebro humano. Sin embargo, en aquel momento se había decidido firmemente que las redes neuronales eran un callejón sin salida en la investigación de la inteligencia artificial. Aunque la primera red neuronal, el Perceptrón, que empezó a ser desarrollada en la década de 1950, había sido aclamada como un primer paso hacia una máquina con inteligencia de nivel humano, un libro de 1969 escrito por Marvin Minsky (ver Adiós, Marvin Minsky, padre de la inteligencia artificial) y Seymour Papert, del MIT, llamado Perceptrones, demostró matemáticamente que estas redes sólo podían realizar las funciones más básicas. En aquel momento sólo tenían dos capas de neuronas, una capa de entrada y una capa de salida. Las redes con más capas entre las neuronas de entrada y de salida podían, en teoría, resolver una gran variedad de problemas, pero nadie sabía cómo entrenarlas, y así, en la práctica, eran inútiles. A excepción de unos pocos irreductibles como Hinton, Perceptrones provocó que la mayoría de la gente renunciara completamente a las redes neuronales.
nEl avance de Hinton, en 1986, fue demostrar que la retropropagación servía para entrenar una red neuronal profunda, es decir una con más de dos o tres capas. Pero fue necesario que pasaran otros 26 años antes de que el aumento del poder computacional diera por bueno el descubrimiento. Un artículo publicado en 2012 por Hinton y dos de sus estudiantes de Toronto (uno de ellos ganador de Innovadores menores de 35 globales en 2015) demostró que las redes neuronales profundas, entrenadas con retropropagación, superaban a los sistemas más avanzados de reconocimiento de imágenes. El "aprendizaje profundo" despegó. Para el mundo exterior, la IA parecía despertar de la noche a la mañana. Para Hinton, era una recompensa largamente merecida.
nDistorsión de la realidad
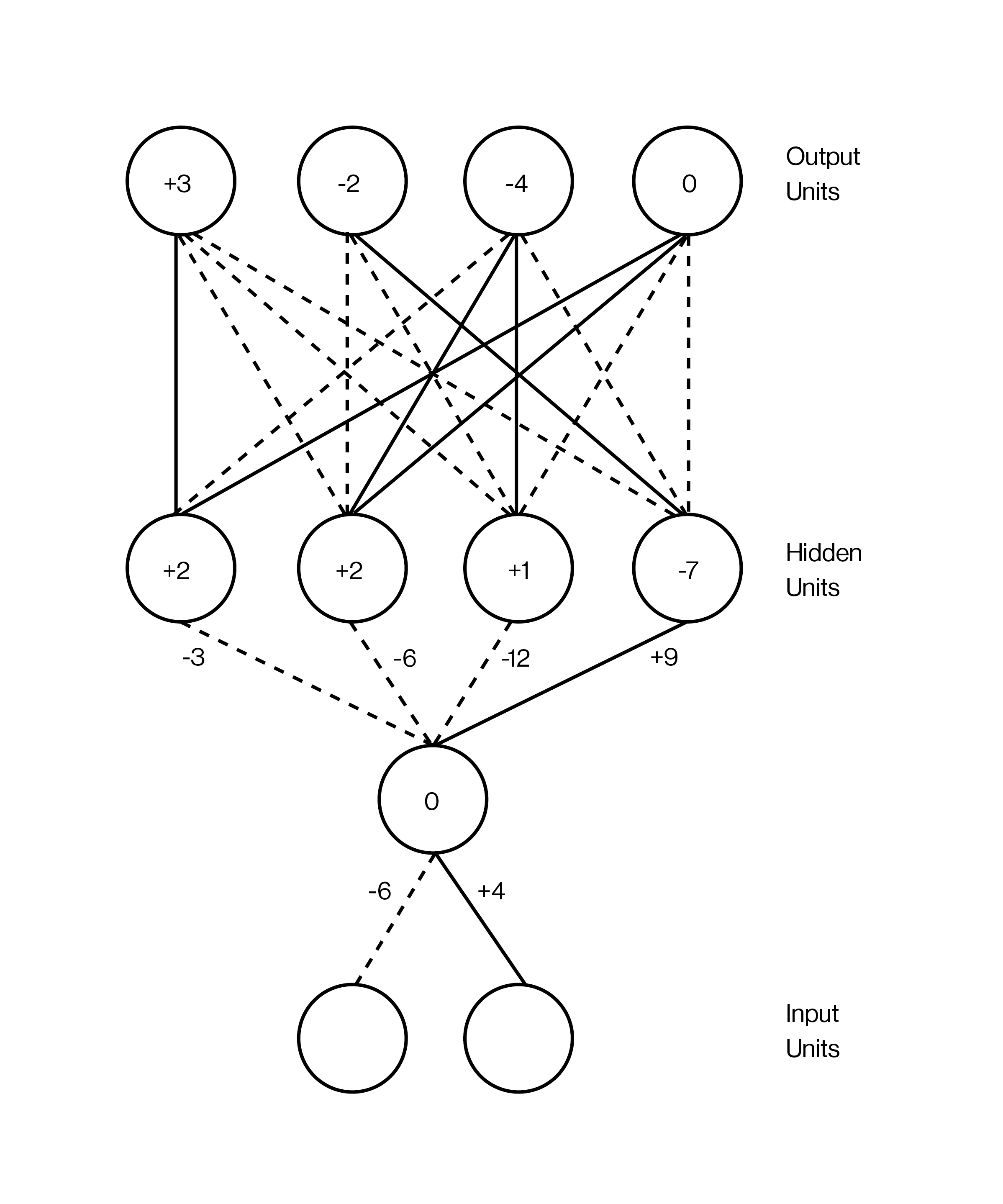
nUna red neuronal se representa como un sándwich club, con las capas apiladas una encima de la otra. Las capas contienen neuronas artificiales, que son pequeñas unidades computacionales que se excitan, como se excita una neurona real, y transmiten esa excitación a las otras neuronas vecinas. La excitación de una neurona se representa por un número, como 0,13 ó 32,39, que representa lo excitada que está. Y hay otro número crucial, en cada una de las conexiones entre dos neuronas, que determina cuánta excitación debe pasar de una a otra. Ese número determina la fuerza de las sinapsis entre las neuronas en el cerebro. Cuando el número es más alto, la conexión es más fuerte, por lo que la excitación de una fluye más a la otra.
n
Esquema: Diagrama del trabajo seminal sobre "propagación de errores" de Hinton, David Rumelhart y Ronald Williams.
nUna de las aplicaciones más exitosas de las redes neuronales profundas es el reconocimiento de imágenes, como en la escena memorable de Silicon Valley de HBO, donde el equipo construye un programa que puede decir si hay un perrito caliente en una imagen. Programas como ese realmente existen (ver Esta máquina predice el riesgo de alzhéimer con más precisión que los médicos), y no hubieran sido posibles hace una década. Para que funcionen, el primer paso es obtener una imagen. Digamos, por simplicidad, que se trata de una pequeña imagen en blanco y negro de 100 píxeles de ancho y 100 píxeles de alto. Se alimenta esta imagen a la red neuronal estableciendo la excitación de cada neurona simulada en la capa de entrada para que sea igual al brillo de cada píxel. Esa es la capa inferior del sándwich: 10.000 neuronas (100x100) que representan el brillo de cada píxel en la imagen.
nA continuación se conecta esta gran capa de neuronas a otra gran capa de neuronas por encima de ella, digamos unas miles, y estas a su vez a otra capa de otras miles de neuronas, y así sucesivamente para unas pocas capas. Por último, en la capa superior del sándwich, la capa de salida, hay sólo dos neuronas, una que representa "perrito caliente" y la otra que representa "no perrito caliente". La idea es enseñar a la red neuronal a excitar sólo la primera de esas neuronas si hay un perro caliente en la imagen, y sólo la segunda si no lo hay. La técnica de retropropagación, la técnica sobre la que Hinton ha construido su carrera, es el método para hacerlo.
nLa retroprop es notablemente simple, aunque funciona mejor con grandes cantidades de datos. Es por eso que el big data es tan importante en la inteligencia artificial, por qué Facebook y Google están tan hambrientos por ellos (ver Una máquina de Google logra reconocer objetos que solo ha visto una vez) y por qué el Instituto Vector decidió establecerse en la misma calle que cuatro de los hospitales más grandes de Canadá y desarrollar acuerdos de cesión de datos con ellos.
nEn este caso, los datos toman la forma de millones de imágenes, algunas con perritos calientes y otras sin; el truco es que estas fotos están etiquetadas en función de si tienen o no perritos calientes. Cuando al principio se crea la red neuronal, las conexiones entre las neuronas pueden tener pesos aleatorios, números aleatorios que dicen cuánta excitación pasar a lo largo de cada conexión. Es como si las sinapsis del cerebro no se hubieran sintonizado todavía. El objetivo de la retroprop es cambiar esos parámetros para que la red funcione, de modo que cuando pases una imagen de un perrito caliente a la capa más baja, la neurona "perrito caliente" de la capa más alta acabe excitándose.
nSupongamos que usted toma su primera imagen de entrenamiento, la imagen de un piano. Primero convierte las intensidades de los píxeles de la imagen de 100x100 en 10.000 números, uno para cada neurona en la capa inferior de la red. A medida que la excitación se extienda por la red de acuerdo a las fuerzas de conexión entre las neuronas en las capas adyacentes, acabará en esa última capa, la de las dos neuronas que dicen si hay un perrito caliente en la imagen. Puesto que la imagen es de un piano, idealmente la neurona del "perrito caliente" debe tener un cero en ella, mientras que la neurona del "no perrito caliente" debe tener un número alto. Pero digamos que no funciona de esa manera. Digamos que la red está equivocada sobre esta imagen. La retroprop es un procedimiento para to ear la fuerza de cada conexión en la red para que se arregle el error para un ejemplo de entrenamiento dado.
nLa forma de hacerlo es empezar con las dos últimas neuronas y averiguar lo equivocadas que están: ¿cuánta diferencia hay entre los que deberían haber sido los números de excitación y los que realmente eran? Una vez hecho esto, se echa un vistazo a cada una de las conexiones que conducen a esas neuronas, las que están en la siguiente capa inferior, y se averigua su contribución al error. El proceso se repite hasta que se haya recorrido todo el camino hasta el primer conjunto de conexiones, en la parte inferior de la red. En ese momento usted sabe cuánto contribuyó cada conexión individual al error general, y en un paso final, se cambia cada uno de los pesos en la dirección que mejor reduzca el error en general. La técnica se llama "retropropagación" porque estás "propagando" errores hacia atrás (o hacia abajo) a través de la red, a partir de la salida.
nLo increíble es que cuando se hace esto con millones o miles de millones de imágenes, la red comienza a ser bastante buena en decir si una imagen tiene un perrito caliente en ella. Y lo que es aún más notable es que las capas individuales de estas redes de reconocimiento de imágenes empiezan a ser capaces de "ver" imágenes de la misma manera que nuestro propio sistema visual. Es decir, la primera capa puede acabar detectando los bordes, en el sentido de que sus neuronas se excitan cuando hay bordes y no se excitan cuando no los hay; la capa por encima de esa podría ser capaz de detectar conjuntos de bordes, como las esquinas; la capa por encima podría empezar a ver formas; y la capa por encima de esta podría comenzar a encontrar cosas como "perrito abierto" o "perrito cerrado", en el sentido de tener neuronas que respondan a ambos casos. La red se autorganiza, en otras palabras, en capas jerárquicas sin haber sido jamás explícitamente programadas de esa manera.
nnUna verdadera inteligencia no deja de funcionar cuando se cambia ligeramente el problema.
n
Esto es lo que ha cautivado a todo el mundo. No es sólo que las redes neuronales sean buenas a la hora de clasificar imágenes de perritos calientes o lo que sea: parecen capaces de construir representaciones de ideas. Esto se ve aún más claro con el texto. Puede alimentarse una red con textos de Wikipedia, de muchos miles de millones de palabras de largo. Con ellos, la red podrá producir, para cada palabra, una gran lista de números que corresponden a la excitación de cada neurona en una capa. Si se piensa en cada uno de estos números como una coordenada en un espacio complejo, esencialmente lo que se está haciendo es encontrar un punto, conocido en este contexto como un vector, para cada palabra en algún lugar de ese espacio. Ahora, entrene su red de tal manera que las palabras que aparezcan cerca unas de otras en las páginas de la Wikipedia terminen con coordenadas similares, y voilà, pasa algo loco: las palabras que tienen significados similares empiezan a aparecer cerca una de la otra en el espacio. Es decir, "loco" y "desquiciado" tendrán coordenadas cercanas entre sí, como "tres" y "siete", y así sucesivamente. Es más, la llamada aritmética vectorial hace posible, por ejemplo, restar el vector de "Francia" del vector de "París", añadir el vector de "Italia" y terminar en los alrededores de "Roma". Funciona sin que nadie le diga a la red explícitamente que Roma es a Italia como París es a Francia.
n"Es increíble. Es chocante", dice Hinton. Las redes neuronales pueden compararse con la tarea de tratar de tomar cosas (imágenes, palabras, grabaciones de alguien que habla, datos médicos) y ponerlas en lo que los matemáticos llaman un espacio vectorial de alta dimensión, donde la proximidad o la distancia entre las cosas refleja alguna característica importante del mundo real. Hinton cree que esto es lo que hace el propio cerebro. El experto detalla: "Si quieres saber lo que es un pensamiento, puedo expresarlo para ti en una cadena de palabras. Puedo decir: 'John pensó,"Whoops"'. Pero si usted pregunta: '¿cuál es el pensamiento?, ¿qué significa para Juan tener ese pensamiento?', no es que dentro de su cabeza haya una apertura de comillas y un 'Whoops' y un cierre de comillas, o siquiera una versión limpia de eso. Dentro de su cabeza hay un gran patrón de actividad neuronal". Los grandes patrones de actividad neuronal, si eres un matemático, pueden ser capturados en un espacio vectorial, con la actividad de cada neurona correspondiente a un número, y cada número a una coordenada de un vector muy grande. A juicio de Hinton, así es el pensamiento: una danza de vectores.
n
Foto: Geoffrey Hinton. Crédito: Cortesía de Google.
nNo es casualidad que la emblemática institución de inteligencia artificial de Toronto fuera bautizada en honor a este fenómeno. Hinton fue el que sugirió el nombre de Instituto Vector.
nEl experto crea una especie de campo de distorsión de la realidad, un aire de certeza y entusiasmo, que da la sensación de que no hay nada que los vectores no puedan hacer. Después de todo, mira lo que ya han sido capaces de hacer: los coches que se conducen solos, ordenadores que detectan el cáncer, máquinas que traducen al instante el idioma hablado. ¡Y mira a este encantador científico británico hablando del descenso del gradiente en espacios de gran dimensión!
nPero al salir de la habitación, uno recuerda: estos sistemas de "aprendizaje profundo" siguen siendo bastante tontos, a pesar de lo inteligentes que a veces parecen (ver Los siete grandes errores de quienes predicen el futuro de la inteligencia artificial). Un ordenador que ve una imagen de un montón de rosquillas apiladas sobre una mesa y la rotula, automáticamente, como "un montón de rosquillas apiladas sobre una mesa" parece entender el mundo; pero cuando ese mismo programa ve una foto de una niña cepillándose los dientes y dice: "El niño está sosteniendo un bate de béisbol", te das cuenta de lo mínima que es esa comprensión en realidad, si es que alguna vez la hubo.
nLas redes neuronales no son más que reconocedores inconscientes de patrones difusos y, tan útiles como los reconocedores de patrones difusos puedan ser (de ahí la prisa por integrarlos en casi todo tipo de software), representan, en el mejor de los casos, una forma limitada de inteligencia, una que es fácilmente engañada (ver Los ordenadores ven mejor que los humanos hasta que alguien intenta engañarlos). Una red neuronal profunda que reconoce imágenes puede verse totalmente obstaculizada cuando se cambia un solo píxel, o se añade ruido visual que es imperceptible para un ser humano. De hecho, casi tan a menudo como encontramos nuevas formas de aplicar el aprendizaje profundo, descubrimos más sobre sus límites. Los coches autónomos pueden fallar al orientarse en condiciones que nunca había visto antes. Las máquinas tienen problemas para analizar frases que exigen una comprensión de sentido común de cómo funciona el mundo.
nEl aprendizaje profundo, de alguna manera, imita lo que ocurre en el cerebro humano, pero sólo de una manera superficial, lo que tal vez explica por qué su inteligencia a veces puede parecer tan superficial. De hecho, la retroprop no fue descubierta al profundizar hondo en el cerebro, decodificando el pensamiento mismo; surgió a partir de modelos de cómo los animales aprenden por ensayo y error en viejos experimentos de condicionamiento clásico. Y la mayor parte de los grandes saltos que se produjeron a medida que se desarrolló no implicaban nuevos aportes sobre neurociencia; fueron mejoras técnicas, alcanzadas tras años de matemáticas e ingeniería. Lo que sabemos acerca de la inteligencia no es nada frente a la inmensidad de lo que todavía no sabemos.
nEl profesor asistente en el mismo departamento que Hinton en la Universidad de Toronto David Duvenaud dice que el aprendizaje profundo ha sido un poco como la ingeniería antes de la física. "Alguien escribe un artículo y dice: 'Hice este puente y se mantuvo en pie'. Otro tipo tiene otro artículo: 'Hice este puente y se cayó, pero luego añadí pilares, y entonces se mantuvo en pie'. Entonces los pilares son la repera. Alguien inventa los arcos y, de repente, 'los arcos son geniales'. El investigador añade: "Con la física, puede entenderse de verdad lo que va a funcionar y por qué". Hace poco que, afirma, hemos comenzado a pasar a esa fase de la comprensión real con la inteligencia artificial.
nEl propio Hinton reconoce: "La mayoría de las conferencias consisten en hacer pequeñas variaciones ... en lugar de pensar mucho y decir: '¿De lo que estamos haciendo ahora, qué es lo realmente deficiente? ¿Con qué tiene dificultades? Enfoquémonos en eso'". Puede ser difícil apreciar esto desde el exterior, cuando todo lo que se ve es un gran avance promocionado detrás de otro. Pero la última ola de progresos en la IA ha sido menos ciencia que ingeniería, incluso que remendar. Y aunque hemos empezado a entender mejor qué tipos de cambios mejorarán los sistemas de aprendizaje profundo, estamos todavía a oscuras acerca de cómo funcionan estos sistemas (ver El secreto más oscuro de la inteligencia artificial: ¿por qué hace lo que hace?), o si podrían llegar algún día a ser algo tan poderoso como la mente humana.
nVale la pena preguntarse si hemos exprimido todo lo que se puede sacar de la retroprop. Si es así, eso podría significar un estancamiento en el progreso de la inteligencia artificial.
nPaciencia
nPara ver el próximo gran éxito, el que podría sentar las bases de máquinas con una inteligencia mucho más flexible, probablemente habría que echar un vistazo a la investigación que se parezca a lo que se habría encontrado si se hubiera topado con la retroprop en los años 80: gente inteligente tirando de ideas que todavía no funcionan realmente.
nHace unos meses fui al Centro de Mentes, Cerebros y Máquinas, una iniciativa multinstitucional con sede en el MIT (EEUU), para ver a mi amigo Eyal Dechter defender su tesis doctoral en ciencias cognitivas. Justo antes de que comenzara la charla, su esposa Amy, su perro Ruby, y su hija Susannah estaban revoloteando alrededor, deseándole éxito. En la pantalla había una foto de Ruby, y junto a ella una de Susannah de bebé. Cuando el papá le pidió a Susannah que se señalara a sí misma, ella golpeó feliz su propia foto de bebé con un largo puntero retráctil. Camino de salida de la habitación, ella empujaba un cochecito de juguete detrás de su madre y gritó "¡Buena suerte, papi!" girando la cabeza. "¡Vamo'!", dijo al final. Sólo tiene dos años.
nn"El hecho de que no funcione es sólo una molestia temporal".
n
Eyal comenzó su charla con una pregunta seductora: ¿Cómo es que Susannah, después de dos años de experiencia, puede aprender a hablar, a jugar, a seguir historias? ¿Qué es lo que tiene el cerebro humano que hace que aprenda tan bien? ¿Podrá algún día un ordenador ser capaz de aprender tan rápido y tan fluidamente?
nDamos sentido a los nuevos fenómenos en términos de las cosas que ya entendemos. Descomponemos un área en pedazos y aprendemos las piezas. Eyal es matemático y programador informático, y visualiza las tareas como hacer un flan, como programas de ordenador realmente complejos. Pero para aprender a hacer un flan no hay que aprenderse cada una de las tropecientas microinstrucciones de la receta, como "gira tu codo 30 grados, luego mira hacia la encimera, luego alarga el dedo Índice, luego...". Si se tuviera que hacer eso por cada nueva tarea, el aprendizaje sería demasiado duro, y uno se quedaría con lo que ya sabe. En su lugar, planteamos el programa en términos de pasos de alto nivel, como "batir las claras de huevo", que están a su vez compuestos por subprogramas, como "abrir los huevos" y "separar las yemas".
nLas computadoras no saben hacer eso, y esa es una gran parte de la razón por la que son tontas. Para obtener un sistema de aprendizaje profundo que reconozca un perrito caliente, es posible que se le tenga que alimentar 40 millones de fotos de perritos calientes. Para que Susannah reconozca un perrito caliente, le enseñas un perrito caliente. Y en poco tiempo tendrá una comprensión del lenguaje que va más allá de reconocer que ciertas palabras a menudo aparecen juntas. A diferencia de un ordenador, ella tendrá un modelo en su mente acerca de cómo funciona el mundo entero. Eyal afirma: "Me parece increíble que la gente tenga miedo de que las computadoras roben empleos. No es que los ordenadores no puedan reemplazar a los abogados porque los abogados hagan cosas realmente complicadas. Es porque los abogados leen y hablan con la gente. No es como si estuviéramos cerca. Estamos lejísimos".
nUna verdadera inteligencia no deja de funcionar cuando se cambian ligeramente los requisitos del problema que está tratando de resolver. Y la parte clave de la tesis de Eyal fue su demostración, en principio, de cómo podría conseguirse que un ordenador funcionase de esa manera: aplicar con fluidez lo que ya sabe a nuevas tareas, para propulsar rápidamente su camino de no saber casi nada sobre un nuevo dominio a ser un experto.
nSe trata de un procedimiento que él llama el algoritmo de "exploración-compresión". Logra que una computadora funcione de un modo parecido a un programador que construye una biblioteca de componentes modulares reutilizables en su camino hacia la construcción de programas cada vez más complejos. Sin que se le diga nada sobre un nuevo dominio, el ordenador intenta estructurar el conocimiento sobre él simplemente jugando, consolidando lo que se encuentra y jugando un poco más, como haría un niño humano.
nSu asesor, Joshua Tenenbaum, es uno de los investigadores más citados en inteligencia artificial. El nombre de Tenenbaum salió a relucir en la mitad de las conversaciones que tuve con otros científicos. Algunas de las personas clave de DeepMind, el equipo detrás de AlphaGo, que sorprendió a los científicos informáticos vender en 2016 a un jugador campeón del mundo en el complejo juego de Go (ver La nueva victoria de AlphaGo demuestra una inteligencia imbatible para los humanos), habían trabajado con él en sus postdoctorados. Él está involucrado con una start-up que trata de proporcionar a los coches autónomos una cierta intuición sobre la física básica y las intenciones de los demás conductores, de modo que puedan anticipar mejor qué sucedería en una situación que nunca hayan visto antes, como cuando un camión hace la tijera delante de ellos o cuando alguien trata de incorporarse al tráfico muy agresivamente (ver Menos datos y más psicología para dar sentido común a los coches autónomos).
nLa tesis de Eyal todavía no se traduce en ese tipo de aplicaciones prácticas, y mucho menos en programas que generen titulares por superar a un ser humano. Los problemas en los que Eyal está trabajando "son simplemente muy, muy difíciles", dijo Tenenbaum. "Van a pasar muchas, muchas generaciones", añadió.
nTenenbaum tiene el pelo largo, rizado y canoso, y cuando nos encontramos para tomar un café llevaba una camisa abotonada y pantalones negros. Me dijo que busca inspiración en la historia de la retroprop. Durante décadas, la retroprop fueron matemáticas molonas que en realidad no habían conseguido nada. Hasta que, a medida que los ordenadores se volvieron más rápidos y la ingeniería se hacía más sofisticada, de repente lo hizo. Él espera que suceda lo mismo con su propio trabajo y el de sus estudiantes, "pero podría tardarse otro par de décadas".
nEn cuanto a Hinton, está convencido de que superar las limitaciones de la inteligencia artificial implica construir "un puente entre la informática y la biología". La retroprop fue, bajo este punto de vista, un triunfo de la computación inspirada biológicamente; la idea no vino inicialmente de la ingeniería sino de la psicología. Así que ahora Hinton está tratando de lograr un truco similar.
nLas redes neuronales actuales están hechas de grandes capas planas, pero en el neocórtex humano las neuronas reales están dispuestas no sólo horizontalmente en capas, sino también verticalmente en columnas. Hinton cree saber para qué sirven las columnas. Por ejemplo, en la vista son cruciales para nuestra capacidad de reconocer objetos incluso cuando nuestro punto de vista cambia. Así que está construyendo una versión artificial (las llama cápsulas) para probar la teoría. Por ahora no ha salido bien; las cápsulas no han mejorado demasiado el rendimiento de sus redes. Pero esta era la misma situación en la que había estado con la retroprop durante casi 30 años.
nEl investigador concluye: "Esto tiene que ser correcto sí o sí. El hecho de que no funcione es sólo una molestia temporal".
n